Create an Iceberg Sink Connector
You can use the Iceberg Sink connector to accomplish the following:
-
Write data into Iceberg tables
-
Commit coordination for centralized Iceberg commits
-
Exactly-once delivery semantics
-
Multi-table fan-out
-
Row mutations (update/delete rows), upsert mode
-
Automatic table creation and schema evolution
-
Field name mapping via Iceberg’s column mapping functionality
Prerequisites
Before you can create an Iceberg Sink connector in Redpanda Cloud, you must:
-
Create the Iceberg connector control topic, which cannot be used by other connectors. For details, see Create a Topic.
Limitations
-
Each Iceberg sink connector must have its own control topic, which you should create before creating the connector.
Create an Iceberg Sink connector
To create the Iceberg Sink connector:
-
In Redpanda Cloud, click Connectors in the navigation menu and then click Create Connector.
-
Select Export to Iceberg.
-
On the Create Connector page, specify the following required connector configuration options:
Property name Property key Description Topics to exporttopicsComma-separated list of the cluster topics you want to replicate.
Topics regextopics.regexJava regular expression of topics to replicate. For example: specify
.*to replicate all available topics in the cluster. Applicable only when Use regular expressions is selected.Iceberg control topiciceberg.control.topicThe name of the control topic. You must create this topic before creating the Iceberg connector. It cannot be used by other Iceberg connectors.
Iceberg catalog typeiceberg.catalog.typeThe type of Iceberg catalog. Allowed options are:
REST,HIVE,HADOOP.Iceberg tablesiceberg.tablesComma-separated list of Iceberg table names, which are specified using the format
{namespace}.{table}. -
Click Next. Review the connector properties specified, then click Create.
Advanced Iceberg Sink connector configuration
In most instances, the preceding basic configuration properties are sufficient. If you require additional property settings, then specify any of the following optional advanced connector configuration properties by selecting Show advanced options on the Create Connector page:
| Property name | Property key | Description |
|---|---|---|
|
|
Commit timeout interval in ms. The default is 30000 (30 sec). |
|
|
For multi-table fan-out, the name of the field used to route records to tables. |
|
|
Name of the field containing the CDC operation, |
Map data
Use the appropriate key or value converter (input data format) for your data as follows:
-
JSONwhen your messages are JSON-encoded. SelectMessage JSON contains schemawith theschemaandpayloadfields. If your messages do not contain schema, create Iceberg tables manually. -
AVROwhen your messages contain AVRO-encoded messages, with schema stored in the Schema Registry.
An Iceberg table’s schema is a list of named columns. All data types are either primitives or nested types, which are maps, lists, or structs. A table schema is also a struct type.
See also: Schemas and Data Types
Sinking data produced by Debezium source connector
Debezium connectors produce data in CDC format. The message structure can be flattened by using Debezium built-in New Record State Extraction Single Message Transformation (SMT). Add the following properties to the Debezium connector configuration to make it produce flat messages:
{
...
"transforms", "unwrap",
"transforms.unwrap.type", "io.debezium.transforms.ExtractNewRecordState",
"transforms.unwrap.drop.tombstones", "false",
...
}Depending on your particular use case, you can apply the SMT to a Debezium connector, or to a sink connector that consumes messages that the Debezium connector produces. To enable Apache Kafka to retain the Debezium change event messages in their original format, configure the SMT for a sink connector.
See also: Debezium New Record State Extraction SMT
Use analytical tools with Iceberg
Iceberg serves as a single storage solution for analytical data. It is inexpensive to read from various tools such as AWS Athena, Snowflake, or Apache Spark.
Traditionally, data import involved pushing data to every tool, incurring high costs for data transfer and storage. Alternatively, you could use plain S3 buckets with Avro or CSV files, but this struggles with schema evolution. Apache Iceberg addresses all of these challenges: cost of data transfer, multiple data copies in storage, and support for schema evolution.
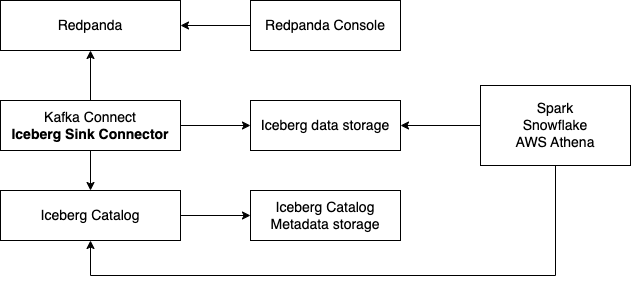
The following example uses:
-
Iceberg REST catalog
-
AWS S3 bucket as the storage for Iceberg files
-
Apache Spark, which reads the Iceberg data from an S3 bucket
version: '3'
services:
redpanda:
image: docker.redpanda.com/redpandadata/redpanda:latest
command:
- redpanda start
- --smp 1
- --overprovisioned
- --node-id 0
- --reserve-memory 0M
- --check=false
- --set redpanda.auto_create_topics_enabled=false
- --kafka-addr PLAINTEXT://0.0.0.0:29092,OUTSIDE://0.0.0.0:9092
- --advertise-kafka-addr PLAINTEXT://redpanda:29092,OUTSIDE://localhost:9092
- --pandaproxy-addr 0.0.0.0:8082
- --advertise-pandaproxy-addr localhost:8082
ports:
- 8081:8081
- 8082:8082
- 9092:9092
- 9644:9644
- 29092:29092
console:
image: docker.redpanda.com/redpandadata/console:latest
restart: on-failure
entrypoint: /bin/sh
command: -c "echo \"$$CONSOLE_CONFIG_FILE\" > /tmp/config.yml; /app/console"
environment:
CONFIG_FILEPATH: /tmp/config.yml
CONSOLE_CONFIG_FILE: |
kafka:
brokers: ["redpanda:29092"]
schemaRegistry:
enabled: true
urls: ["http://redpanda:8081"]
connect:
enabled: true
clusters:
- name: connectors
url: http://connect:8083
ports:
- "8090:8080"
depends_on:
- redpanda
connect:
image: docker.redpanda.com/redpandadata/connectors:latest
hostname: connect
depends_on:
- redpanda
- spark-iceberg
ports:
- "8083:8083"
- "9404:9404"
environment:
CONNECT_CONFIGURATION: |
key.converter=org.apache.kafka.connect.converters.ByteArrayConverter
value.converter=org.apache.kafka.connect.converters.ByteArrayConverter
group.id=connectors-cluster
offset.storage.topic=_internal_connectors_offsets
config.storage.topic=_internal_connectors_configs
status.storage.topic=_internal_connectors_status
config.storage.replication.factor=-1
offset.storage.replication.factor=-1
status.storage.replication.factor=-1
producer.linger.ms=1
producer.batch.size=131072
config.providers=file
config.providers.file.class=org.apache.kafka.common.config.provider.FileConfigProvider
CONNECT_BOOTSTRAP_SERVERS: redpanda:29092
SCHEMA_REGISTRY_URL: http://redpanda:8081
CONNECT_GC_LOG_ENABLED: "false"
CONNECT_HEAP_OPTS: -Xms512M -Xmx512M
CONNECT_LOG_LEVEL: info
CONNECT_TOPIC_LOG_ENABLED: "true"
CONNECT_PLUGIN_PATH: "/opt/kafka/connect-plugins"
spark-iceberg:
image: tabulario/spark-iceberg:3.4.1_1.3.1
build: spark/
depends_on:
- rest
volumes:
- ./warehouse:/home/iceberg/warehouse
environment:
- AWS_ACCESS_KEY_ID=${AWS_ACCESS_KEY_ID}
- AWS_SECRET_ACCESS_KEY=${AWS_SECRET_ACCESS_KEY}
- AWS_REGION=${AWS_REGION}
ports:
- 8888:8888
- 8080:8080
- 10000:10000
- 10001:10001
rest:
image: tabulario/iceberg-rest:0.6.0
ports:
- 8181:8181
environment:
- AWS_ACCESS_KEY_ID=${AWS_ACCESS_KEY_ID}
- AWS_SECRET_ACCESS_KEY=${AWS_SECRET_ACCESS_KEY}
- AWS_REGION=${AWS_REGION}
- CATALOG_WAREHOUSE=s3://bucket-name/
- CATALOG_IO__IMPL=org.apache.iceberg.aws.s3.S3FileIOUse Spark-SQL to:
-
List databases:
spark-sql ()> show databases; testdb -
Show tables in database:
spark-sql ()> show tables in testdb; testtable -
Select data from table:
spark-sql ()> select * from testdb.testtable;
Use with AWS Glue Data Catalog and AWS Lake Formation
The connector can be used with the AWS Glue Data Catalog and the AWS Lake Formation service. AWS Lake Formation only lets you use the role form of authentication. The connectors UI does not support Lake Formation-specific properties. Use the JSON editor instead. Sample configuration:
{
...
"iceberg.catalog.client.assume-role.region": "the-region",
"iceberg.catalog.client.assume-role.arn": "arn:aws:iam::account-number:role/role-name",
"iceberg.catalog.glue.account-id": "NNN",
"iceberg.catalog.catalog-impl": "org.apache.iceberg.aws.glue.GlueCatalog",
"iceberg.catalog.client.assume-role.tags.LakeFormationAuthorizedCaller": "iceberg-connect",
"iceberg.catalog.io-impl": "org.apache.iceberg.aws.s3.S3FileIO",
"iceberg.catalog": "catalog_name",
"iceberg.catalog.warehouse": "s3://bucket-name/my/data",
"iceberg.catalog.s3.path-style-access": "true"
}Test the connection
After the connector is created, execute SELECT query on the Iceberg table to verify data. It may take a couple of minutes for the records to be visible in Iceberg. Check connector state and logs for errors.
Troubleshoot
Iceberg connection settings are checked for validity during first data processing. The connector can be successfully created with incorrect configuration and fail only when there are messages in source topic to process.
| Message | Action |
|---|---|
NoSuchTableException: Table does not exist |
Make sure Iceberg table exists and the connector iceberg.tables configuration contains correct table name in |
UnknownHostException: incorrectcatalog: Name or service not known |
Cannot connect to Iceberg catalog. Check if Iceberg catalog URI is correct and accessible. |
DataException: An error occurred converting record, topic: topicName, partition, 0, offset: 0 |
The connector cannot read the message format. Ensure the connector mapping configuration and data format are correct. |
NullPointerException: Cannot invoke "java.lang.Long.longValue()" because "value" is null |
The connector cannot read the message format. Ensure the connector mapping configuration and data format are correct. |
Suggested reading
-
For details about the Iceberg Sink connector configuration properties, see Iceberg-Kafka-Connect
-
For details about the Iceberg Sink connector internals, see Iceberg-Kafka-Connect documentation