Introduction to Redpanda
Distributed systems often require data and system updates to happen as quickly as possible. In software architecture, these updates can be handled with either messages or events.
-
With messages, updates are sent directly from one component to another to trigger an action.
-
With events, updates indicate that an action occurred at a specific time, and are not directed to a specific recipient.
An event is simply a record of something changing state. For example, the event of a credit card transaction includes the product purchased, the payment, the delivery, and the time of the purchase. The event occurred in the purchasing component, but it also impacted the inventory, the payment processing, and the shipping components.
In an event-driven architecture, all actions are defined and packaged as events to precisely identify individual actions and how they’re processed throughout the system. Instead of processing updates in consecutive order, event-driven architecture lets components process events at their own pace. This helps developers build fast and scalable systems.
What is Redpanda?
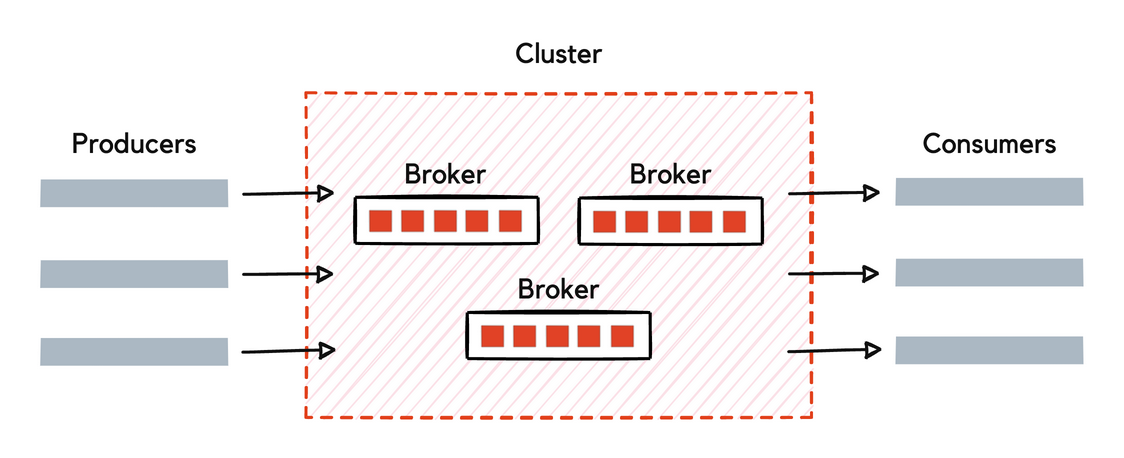
Redpanda is an event streaming platform: it provides the infrastructure for streaming real-time data.
Producers are client applications that send data to Redpanda in the form of events. Redpanda safely stores these events in sequence and organizes them into topics, which represent a replayable log of changes in the system.
Consumers are client applications that subscribe to Redpanda topics to asynchronously read events. Consumers can store, process, or react to the events.
Redpanda decouples producers from consumers to allow for asynchronous event processing, event tracking, event manipulation, and event archiving. Producers and consumers interact with Redpanda using the Apache Kafka® API.
| Event-driven architecture (Redpanda) | Message-driven architecture |
|---|---|
Producers send events to an event processing system (Redpanda) that acknowledges receipt of the write. This guarantees that the write is durable within the system and can be read by multiple consumers. |
Producers send messages directly to each consumer. The producer must wait for acknowledgement that the consumer received the message before it can continue with its processes. |
Event streaming lets you extract value out of each event by analyzing, mining, or transforming it for insights. You can:
-
Take one event and consume it in multiple ways.
-
Replay events from the past and route them to new processes in your application.
-
Run transformations on the data in real-time or historically.
-
Integrate with other event processing systems that use the Kafka API.
Redpanda differentiators
Redpanda is less complex and less costly than any other commercial mission-critical event streaming platform. It’s fast, it’s easy, and it keeps your data safe.
-
Redpanda is designed for maximum performance on any data streaming workload.
It can scale up to use all available resources on a single machine and scale out to distribute performance across multiple nodes. Built on C++, Redpanda delivers greater throughput and up to 10x lower p99 latencies than other platforms. This enables previously unimaginable use cases that require high throughput, low latency, and a minimal hardware footprint.
-
Redpanda is packaged as a single binary: it doesn’t rely on any external systems.
It’s compatible with the Kafka API, so it works with the full ecosystem of tools and integrations built on Kafka. Redpanda can be deployed on bare metal, containers, or virtual machines in a data center or in the cloud. And Redpanda Console makes it easy to set up, manage, and monitor your clusters. Additionally, Tiered Storage lets you offload log segments to object storage in near real-time, providing long-term data retention and topic recovery.
-
Redpanda uses the Raft consensus algorithm throughout the platform to coordinate writing data to log files and replicating that data across multiple servers.
Raft facilitates communication between the nodes in a Redpanda cluster to make sure that they agree on changes and remain in sync, even if a minority of them are in a failure state. This allows Redpanda to tolerate partial environmental failures and deliver predictable performance, even at high loads.
-
Redpanda provides data sovereignty.
With the Bring Your Own Cloud (BYOC) offering, you deploy Redpanda in your own virtual private cloud, and all data is contained in your environment. Redpanda handles provisioning, monitoring, and upgrades, but you manage your streaming data without Redpanda’s control plane ever seeing it.
Redpanda Streaming versions
You can deploy Redpanda in a self-hosted environment (Redpanda Streaming) or as a fully managed cloud service (Redpanda Cloud).
Redpanda Streaming version numbers follow the convention AB.C.D, where AB is the two-digit year, C is the feature release, and D is the patch release. For example, version 22.3.1 indicates the first patch release on the third feature release of the year 2022. Patch releases include bug fixes and minor improvements, with no change to user-facing behavior. New and enhanced features are documented with each feature release.
Redpanda Cloud releases on a continuous basis and uptakes Redpanda Streaming versions.
Next steps
-
To spin up a Redpanda cluster to try it out, see Redpanda Quickstart.
-
To learn more about Redpanda, see How Redpanda Works.
-
For information about a Redpanda Streaming deployment, see Redpanda Licensing.
-
For information about a Redpanda Cloud deployment, see Redpanda Cloud Overview.
