High Availability in Kubernetes
Redpanda is designed to ensure data integrity and high availability (HA), even at high-throughput levels.
Kubernetes offers an ideal environment for managing and scaling Redpanda. By deploying Redpanda on Kubernetes, you can ensure HA through Kubernetes-native features, benefit from automated rollouts and rollbacks, and take advantage of the platform’s self-healing properties.
Deployment strategies
Consider the following Redpanda deployment strategies for the most common types of failures.
| Failure | Impact | Mitigation strategy |
|---|---|---|
Broker failure |
Loss of function for an individual broker or for any virtual machine (VM) that hosts the broker |
Multi-broker deployment |
Rack or switch failure |
Loss of brokers/VMs hosted within that rack, or loss of connectivity to them |
Multi-broker deployment spread across multiple racks or network failure domains |
Data center failure |
Loss of brokers/VMs hosted within that data center, or loss of connectivity to them |
Multi-AZ or replicated deployment |
Region failure |
Loss of brokers/VMs hosted within that region, or loss of connectivity to them |
Geo-stretch (latency dependent) or replicated deployment |
Global, systemic outage (DNS failures, routing failures) |
Complete outage for all systems and services impacting customers and staff |
Offline backups, replicas in 3rd-party domains |
Data loss or corruption (accidental or malicious) |
Corrupt or unavailable data that also affects synchronous replicas |
Offline backups |
HA deployment options
This section explains the trade-offs with different HA configurations.
Multi-broker deployment
Redpanda is designed to be deployed in a cluster that consists of at least three brokers. Although clusters with a single broker are convenient for development and testing, they aren’t resilient to failure. Adding brokers to a cluster provides a way to handle individual broker failures. You can also use [rack awareness] to assign brokers to different racks, which allows Redpanda to tolerate the loss of a rack or failure domain.
By default, the Redpanda Helm chart deploys three Redpanda brokers in separate Pods that are all managed by a StatefulSet. If the Redpanda broker inside a Pod crashes, Kubernetes automatically restarts the Pod.
The Redpanda Helm chart also uses podAntiAffinity rules to stop the Kubernetes scheduler from placing multiple Redpanda brokers on the same node. These rules offer two benefits:
-
To minimize the risk of data loss by ensuring that a node’s failure results in the loss of only one Redpanda broker.
-
To prevent resource contention between brokers by ensuring they are never co-located on the same node.
See also: Single-AZ deployments
Multi-AZ deployment
An availability zone (AZ) consists of one or more data centers served by high-bandwidth links with low latency (and typically within a close distance of one another). All AZs have discrete failure domains (power, cooling, fire, and network), but they also have common-cause failure domains, such as catastrophic events, that affect their geographical location. To safeguard against such possibilities, a cluster can be deployed across multiple AZs by configuring each AZ as a rack using rack awareness.
Implementing Raft internally ensures that Redpanda can tolerate losing a minority of replicas for a given topic or for controller groups. For this to translate to a multi-AZ deployment, however, it’s necessary to deploy to at least three AZs (affording the loss of one zone). In a typical multi-AZ deployment, cluster performance is constrained by inter-AZ bandwidth and latency.
See also: Multi-AZ deployments
For greater resilience in Kubernetes:
-
Use
nodeAffinityrules to control the placement of Pods based on node labels indicating zones or regions.Kubernetes provides a scheduling feature known as
nodeAffinitythat allows you to specify conditions on which a Pod can or cannot be scheduled based on the node labels. This is particularly useful for deploying workloads in a multi-zone or multi-region setup, ensuring high availability and resilience. -
If you use the Redpanda Operator, deploy multiple instances of it across multiple AZs on multiple nodes.
The Redpanda Operator has built-in leader election. When the leader (the active Redpanda Operator instance) fails or becomes unreachable, one of the other instances automatically takes over the leadership role, ensuring uninterrupted management of Redpanda instances.
By distributing instances across multiple AZs, you protect against the failure of a whole availability zone. Even if one zone goes down, an instance from another zone can take over.
See also:
Multi-region deployment
A multi-region deployment is similar to a multi-AZ deployment, in that it needs at least three regions to counter the loss of a single region. Note that this deployment strategy increases latency due to the physical distance between regions. Consider the following strategies to mitigate this problem:
-
Manually configure leadership of each partition to ensure that leaders are congregated in the primary region (closest to the producers and consumers).
-
If your produce latency exceeds your requirements, you can configure producers to have
acks=1instead ofacks=all. This reduces latency by only waiting for the leader to acknowledge, rather than waiting for all brokers to respond. However, using this configuration can decrease message durability. If the partition leader goes offline, you may lose any messages that are acknowledged but not yet replicated.
Multi-cluster deployment
In a multi-cluster deployment, each cluster is configured using one of the other HA deployments, along with standby clusters or Remote Read Replica clusters in one or more remote locations. A standby cluster is a fully functional cluster that can handle producers and consumers. A remote read replica is a read-only cluster that can act as a backup for topics. To replicate data across clusters in a multi-cluster deployment, use one of the following options:
Alternatively, you could dual-feed clusters in multiple regions. Dual feeding is the process of having producers connect to your cluster across multiple regions. However, this introduces additional complexity onto the producing application. It also requires consumers that have sufficient deduplication logic built in to handle offsets, since they won’t be the same across each cluster.
HA features in Kubernetes
Kubernetes includes the following high-availability features:
-
Automatic failovers: Kubernetes has built-in controllers to detect Pod failures and recreate them, ensuring service continuity.
-
Scaling: Use Kubernetes Horizontal Pod Autoscaler (HPA) to scale Redpanda Pods based on metrics like CPU and memory usage.
-
Network policies: Use Kubernetes network policies to control the communication between Redpanda Pods, ensuring secure data transfer.
Node pools
If you use managed Kubernetes services such as Amazon EKS, consider creating dedicated node pools for your Redpanda deployment. These node pools can have machines optimized for the workload with high I/O capacity or more CPU and memory resources. Dedicated node pools ensure that Redpanda brokers do not compete for resources with other workloads in your Kubernetes cluster. This is particularly useful when you need to guarantee specific performance for your Redpanda deployment. Node pools are also beneficial during scaling operations. By having dedicated node pools, you can scale your Redpanda cluster without affecting other applications.
Storage
Data persistence and protection are crucial for high availability:
-
Persistent Volume Claims (PVCs): By default, the Redpanda Helm chart uses the default StorageClass in your Kubernetes cluster to create one PVC for each Redpanda broker, ensuring data is stored persistently. These PVCs ensure that if a Pod is terminated or crashes, the data isn’t lost, and when a new Pod starts, it reattaches to the existing PVC.
-
Storage Class: The dynamic nature of Kubernetes deployments benefits from StorageClasses that automatically provision new PersistentVolumes (PVs) for each PVC. For Redpanda, choose a StorageClass that supports high I/O operations, especially if backed by high-performance NVMe storage.
See also:
HA features in Redpanda
Redpanda includes the following high-availability features:
Replica synchronization
A cluster’s availability is directly tied to replica synchronization. Brokers can be either leaders or replicas (followers) for a partition. A cluster’s replica brokers must be consistent with the leader to be available for consumers and producers.
-
The leader writes data to the disk. It then dispatches append entry requests to the followers in parallel with the disk flush.
-
The replicas receive messages written to the partition of the leader. They send acknowledgments to the leader after successfully replicating the message to their internal partition.
-
The leader sends an acknowledgment to the producer of the message, as determined by that producer’s
acksvalue. Redpanda considers the group consistent after a majority has formed consensus; that is, a majority of participants acknowledged the write.
While Apache Kafka® uses in-sync replicas, Redpanda uses a quorum-based majority with the Raft replication protocol. Kafka performance is negatively impacted when any "in-sync" replica is running slower than other replicas in the In-Sync Replica (ISR) set.
Monitor the health of your cluster with the rpk cluster health command, which tells you if any brokers are down, and if you have any leaderless partitions.
Rack awareness
Rack awareness is one of the most important features for HA. It lets Redpanda spread partition replicas across available brokers in different failure zones. Rack awareness ensures that no more than a minority of replicas are placed on a single rack, even during cluster balancing.
| Make sure you assign separate rack IDs that actually correspond to a physical separation of brokers. |
See also: Enable Rack Awareness
Partition leadership
Raft uses a heartbeat mechanism to maintain leadership authority and to trigger leader elections. The partition leader sends a periodic heartbeat to all followers to assert its leadership. If a follower does not receive a heartbeat over a period of time, then it triggers an election to choose a new partition leader.
See also: Partition leadership elections
Producer acknowledgment
Producer acknowledgment defines how producer clients and broker leaders communicate their status while transferring data. The acks value determines producer and broker behavior when writing data to the event bus.
See also: Producer Acknowledgement Settings
Partition rebalancing
By default, Redpanda rebalances partition distribution when brokers are added or decommissioned. Continuous Data Balancing additionally rebalances partitions when brokers become unavailable or when disk space usage exceeds a threshold.
See also: Cluster Balancing
Tiered Storage and disaster recovery
In a disaster, your secondary cluster may still be available, but you need to quickly restore the original level of redundancy by bringing up a new primary cluster. In a containerized environment such as Kubernetes, all state is lost from pods that use only local storage. HA deployments with Tiered Storage address both these problems, since it offers long-term data retention and topic recovery.
See also: Tiered Storage
| Tiered Storage operates as an asynchronous process and only applies to closed segments. Any open segments or segments existing only in local storage are not recoverable by your new primary cluster. |
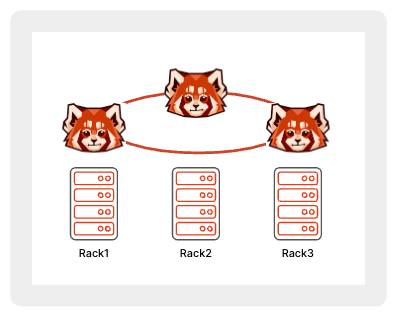
Single-AZ deployments
When deploying a cluster for high availability into a single AZ or data center, you need to ensure that, within the AZ, single points of failure are minimized and that Redpanda is configured to be aware of any discrete failure domains within the AZ. This is achieved with Redpanda’s rack awareness, which deploys n Redpanda brokers across three or more racks (or failure domains) within the AZ.
Single-AZ deployments in the cloud have less network costs than multi-AZ deployments, and you can leverage resilient power supplies and networking infrastructure within the AZ to mitigate against all but total-AZ failure scenarios. You can balance the benefits of increased availability and fault tolerance against any increase in cost, performance, and complexity:
-
Cost: Redpanda operates the same Raft consensus algorithm whether it’s in HA mode or not. There may be infrastructure costs when deploying across multiple racks, but these are normally amortized across a wider datacenter operations program.
-
Performance: Spreading Redpanda replicas across racks and switches increases the number of network hops between Redpanda brokers; however, normal intra-data center network latency should be measured in microseconds rather than milliseconds. Ensure that there’s sufficient bandwidth between brokers to handle replication traffic.
-
Complexity: A benefit of Redpanda is the simplicity of deployment. Because Redpanda is deployed as a single binary with no external dependencies, it doesn’t need any infrastructure for ZooKeeper or for a Schema Registry. Redpanda also includes cluster balancing, so there’s no need to run Cruise Control.
Single-AZ infrastructure
In a single-AZ deployment, ensure that brokers are spread across at least three failure domains. This generally means separate racks, under separate switches, ideally powered by separate electrical feeds or circuits. Also, ensure that there’s sufficient network bandwidth between brokers, particularly considering shared uplinks, which could be subject to high throughput intra-cluster replication traffic. In an on-premises network, this HA configuration refers to separate racks or data halls within a data center.
Cloud providers support various HA configurations:
-
AWS partition placement groups allow spreading hosts across multiple partitions (or failure domains) within an AZ. The default number of partitions is three, with a maximum of seven. This can be combined with Redpanda’s replication factor setting, so each topic partition replica is guaranteed to be isolated from the impact of hardware failure.
-
Microsoft Azure flexible scale sets let you assign VMs to specific fault domains. Each scale set can have up to five fault domains, depending on your region. Not all VM types support flexible orchestration; for example, Lsv2-series only supports uniform scale sets.
-
Google Cloud instance placement policies let you specify how many availability domains you can have (up to eight) when using the Spread Instance Placement Policy.
Google Cloud doesn’t divulge which availability domain an instance has been placed into, so you must have an availability domain for each Redpanda broker. Essentially, this isn’t enabled with rack awareness, but it’s the only possibility for clusters with more than three brokers.
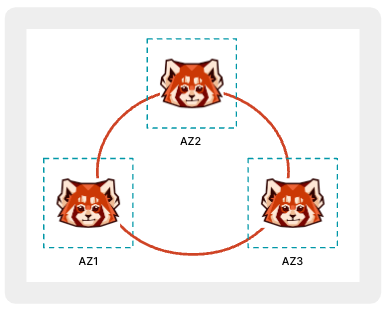
Multi-AZ deployments
In a multi-AZ (availability zone) deployment a single Redpanda cluster has brokers distributed over multiple availability zones. With rack awareness, Redpanda places replicas across brokers in different failure zones, resulting in a cluster that can survive a zone outage.
| Adding a zone does not necessarily increase availability. The replication factor of a given partition is most important. If all of your partitions use a replication factor of three, then adding an additional broker in a fourth zone just means fewer partitions are affected by an outage (since the workload is more spread out). |
The primary reason to deploy across multiple availability zones is to achieve extremely high availability, even at the expense of other considerations. Before choosing this approach, carefully consider your system’s requirements. Some of the considerations of a multi-AZ approach include:
-
Cost: Maintaining presence across multiple availability zones may incur additional costs. You may require additional brokers to hit the minimum requirements for utilizing a multi-AZ deployment. Data sent between availability zones is often chargeable, resulting in additional cloud costs.
-
Performance: A multi-AZ approach introduces additional message latency. Your brokers are further apart in terms of network distance with additional routing hops in place.
-
Complexity: The Redpanda operational complexity is not appreciably increased, but the complexity of your overall cloud solution is. Maintaining presence across availability zones requires additional servers with corresponding maintenance, access control, and standard operational considerations.
Multi-AZ infrastructure requirements
Redpanda requires a minimum of three availability zones when using a multi-AZ approach. Deploying across only two availability zones is problematic. For example, given a cluster with three brokers spread across two availability zones, you either end up with all three brokers in one zone or a pair of brokers in one with a single broker in the other. Either way, it’s possible to lose a majority of your brokers with a single availability zone outage. You lose the ability to form consensus in affected partitions, negating the high availability state you desire.
Multi-AZ optimization
You can configure follower fetching to help ease the cross-AZ cost problems associated with a multi-AZ configuration. This is achieved by configuring consumers to advertise their preferred rack using the client.rack option within their consumer configuration. This allows consumers to read data from their closest replica rather than always reading from a (potentially non-local) partition leader.
| With follower fetching enabled, a consumer chooses the closest replica rather than the leader. This reduces network transfer costs against the possibility of increased end-to-end latency. Make sure to monitor your system to determine if the cost savings are worth this latency risk. |
Multi-AZ example
Redpanda provides an official deployment automation project using Ansible and Terraform to help self-hosted users stand up multi-AZ deployments quickly and efficiently.
Configure Terraform
Configure the appropriate Terraform script for your cloud provider. Within the deployment-automation project, locate the file for your cloud provider and edit the availability_zones parameter. Include each availability zone you intend to use for your deployment. For example, under AWS, edit the aws/main.tf file:
variable "availability_zone" {
description = "The AWS AZ to deploy the infrastructure on"
default = ["us-west-2a", "us-west-2b", "us-west-2c"]
type = list(string)
}Alternatively, you can supply the configuration at the command line:
$ terraform apply -var=availability_zone='["us-west-2a","us-west-2b","us-west-2c"]'Deploy using Terraform and Ansible
After you configure Terraform for your cloud provider and choose availability zones, you can deploy your cluster. The following example deploys a multi-AZ cluster and validates the rack configuration.
# Initialize a private key if you haven’t done so already
ssh-keygen -f ~/.ssh/id_rsa
# Clone the deployment-automation repository
git clone https://github.com/redpanda-data/deployment-automation
# Choose your cloud provider and initialize Terraform
cd deployment-automation/aws # choose one: aws|azure|gcp
terraform init
# Deploy the infrastructure
# (Note: This guidance is based on the assumption that you have cloud credentials available)
terraform apply -var=availability_zone='["us-west-2a","us-west-2b","us-west-2c"]'
# Verify you have correctly specified your racks in the host.ini file:
cd ..
export HOSTS=$(find . -name hosts.ini)
head -4 $HOSTS
[redpanda]
34.102.108.41 ansible_user=adminpanda ansible_become=True private_ip=10.168.0.41 rack=us-west2-a
35.236.32.47 ansible_user=adminpanda ansible_become=True private_ip=10.168.0.39 rack=us-west2-b
35.236.29.38 ansible_user=adminpanda ansible_become=True private_ip=10.168.0.40 rack=us-west2-c
# Ensure the environment is ready
export CLOUD_PROVIDER=aws # or azure or gcp accordingly
export ANSIBLE_COLLECTIONS_PATHS=${PWD}/artifacts/collections
export ANSIBLE_ROLES_PATH=${PWD}/artifacts/roles
export ANSIBLE_INVENTORY=${PWD}/${CLOUD_PROVIDER}/hosts.ini
# Install Ansible Galaxy roles
ansible-galaxy install -r ./requirements.yml
# Provision the cluster with Ansible
ansible-playbook ansible/provision-basic-cluster.yml -i $HOSTS
### Verify that rack awareness is enabled
# SSH into a cluster node substituting the username and hostname from the values above
ssh -i ~/.ssh/id_rsa <username>@<hostname of redpanda node>
# Check to confirm that rack awareness is enabled
rpk cluster config get enable_rack_awareness
true
# Check to confirm that the brokers are assigned to distinct racks
rpk cluster status | grep RACK -A3
ID HOST PORT RACK
0* 34.102.108.41 9092 us-west2-a
1 35.236.32.47 9092 us-west2-b
2 35.236.29.38 9092 us-west2-cUse follower fetching
Use follower fetching to reduce the latency and potential costs involved in a multi-AZ deployment.
# SSH into a node using appropriate credentials
ssh -i ~/.ssh/id_rsa <username>@<hostname of redpanda node>
# Create a topic with 1 partition and 3 replicas
rpk topic create foo -p1 -r3
TOPIC STATUS
foo OK
# Determine which broker is the leader
rpk topic describe foo -a | grep HIGH-WATERMARK -A1
PARTITION LEADER EPOCH REPLICAS LOG-START-OFFSET HIGH-WATERMARK
0 0 1 [0 1 2] 0 3
# Produce 1000 records using rpk
for i in {1..1000}; do echo $(cat /dev/urandom | head -c50 | base64); done | rpk topic produce foo
Produced to partition 0 at offset 0 with timestamp 1687508554559.
Produced to partition 0 at offset 1 with timestamp 1687508554574.
Produced to partition 0 at offset 2 with timestamp 1687508554593.
... 997 more lines ...
# Consume for three seconds, writing debug logs and ignoring regular output
timeout 3 rpk topic consume foo -v --rack us-west2-c 1>/dev/null 2>debug.log
# Filter the debug log to only show lines of interest
cat debug.log | grep -v ApiVersions | egrep 'opening|read'
08:25:14.974 DEBUG opening connection to broker {"addr": "10.168.0.41:9092", "broker": "seed 0"}
08:25:14.976 DEBUG read Metadata v7 {"broker": "seed 0", "bytes_read": 236, "read_wait": "36.312µs", "time_to_read": "534.898µs", "err": null}
08:25:14.977 DEBUG opening connection to broker {"addr": "34.102.108.41:9092", "broker": "0"}
08:25:14.980 DEBUG read ListOffsets v4 {"broker": "0", "bytes_read": 51, "read_wait": "16.19µs", "time_to_read": "1.090468ms", "err": null}
08:25:14.981 DEBUG opening connection to broker {"addr": "34.102.108.41:9092", "broker": "0"}
08:25:14.982 DEBUG read Fetch v11 {"broker": "0", "bytes_read": 73, "read_wait": "17.705µs", "time_to_read": "858.613µs", "err": null}
08:25:14.982 DEBUG opening connection to broker {"addr": "35.236.29.38:9092", "broker": "2"}
08:25:14.989 DEBUG read Fetch v11 {"broker": "2", "bytes_read": 130337, "read_wait": "54.712µs", "time_to_read": "4.466249ms", "err": null}
08:25:17.946 DEBUG read Fetch v11 {"broker": "2", "bytes_read": 0, "read_wait": "41.144µs", "time_to_read": "2.955927224s", "err": "context canceled"}
08:25:17.947 DEBUG read Fetch v11 {"broker": "0", "bytes_read": 22, "read_wait": "175.952µs", "time_to_read": "500.832µs", "err": null}