Sizing Guidelines
For best performance, size your Redpanda cluster to handle the volume of data being produced, replicated, and consumed. The following variables affect cluster sizing:
-
Throughput of data (after compression, if applied)
-
Topic replication factor
-
Number of producers and consumers
Throughput and retention requirements can cause bottlenecks in the system. On an undersized cluster, clients could saturate the available network bandwidth, a disk could run out of IOPS and be unable to keep up with writes, or you could simply run out of disk space. On an oversized Redpanda cluster, you could overpay for unnecessary infrastructure. For sizing estimates and advice for various throughput and retention scenarios, see Sizing Use Cases.
In general, choose the number of nodes based on the following criteria, and add nodes for fault tolerance. This ensures that the system can operate with full throughput in a degraded state.
-
Total network bandwidth must account for maximum simultaneous writes and reads, multiplied by the replication factor.
-
Have a minimum of 2 GB memory for each core, but more memory is better.
-
Have a minimum of 4 MB of memory for each topic partition replica. You can enforce this requirement in the tunable
topic_memory_per_partitionproperty. -
Use Tiered Storage to unify historical and real-time data.
-
For AWS, test with either i3en, i4i, or is4gen; for GCP, test with n2-standard (GCP); and for Azure, test with lsv2. In general, choose instance types that prioritize storage and network performance.
-
Run hardware and Redpanda benchmark tests for a performance baseline.
Sizing considerations
Network
To understand the network usage of a basic Redpanda cluster, consider a cluster with three nodes, a topic with a single partition and a replication factor of three, and a single producer and consumer. For every 75 MB written to the partition’s leader, 150 MB is transmitted across the network to other nodes for replication, and 75 MB is transmitted to the consumer.
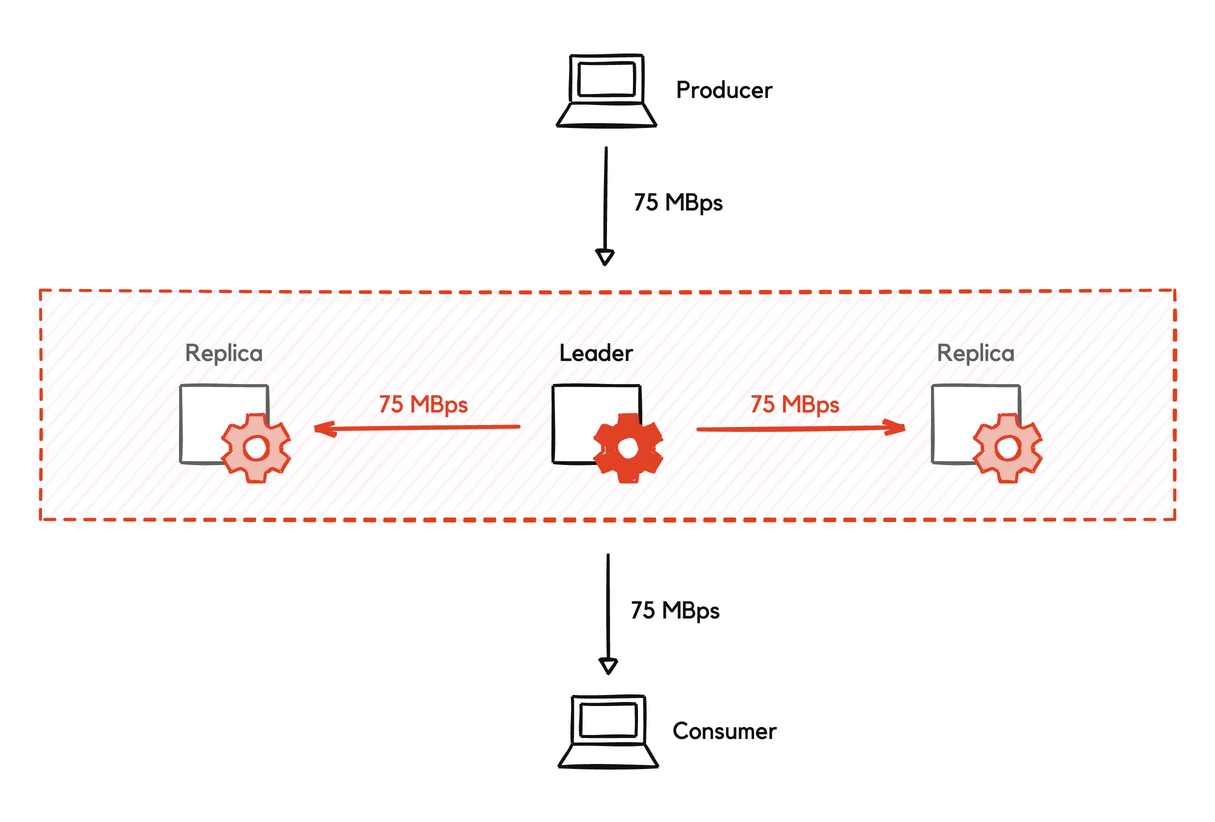
The 150 MB/sec of bandwidth for replication is full duplex (where each byte sent by a broker is received by some other broker). The 75 MB/sec producer and consumer flows, however, are half-duplex, because the client endpoint in each case is outside of the cluster. In a well-balanced scenario, the intra-cluster bandwidth is 225 MB for incoming and outgoing flows:
-
150 MB/sec of intra-cluster full duplex bandwidth
-
75 MB/sec of ingress from producers half-duplex bandwidth
-
75 MB/sec of egress to consumers half-duplex bandwidth
Even with the same amount of data produced, increasing the replication factor or the number of consumers increases bandwidth utilization.
It’s important to measure the network bandwidth between nodes, and between clients and nodes, to make sure that you’re getting the expected performance from the network. This is especially important for cloud deployments where network bandwidth is not always guaranteed. Short tests may give unrealistically good results because of burst bandwidth, where instances can use a network I/O credit mechanism to burst for a limited time beyond their baseline bandwidth. To get realistic results, soak test the network to understand how it behaves over longer periods of time.
The following example uses iPerf3 to test the network bandwidth between two Debian-based servers. To do a full network stress test, run iPerf3 for every combination of network routes.
redpanda1:~$ sudo apt -y update; sudo apt -y install iperf3
redpanda1:~$ iperf3 -s
-----------------------------------------------------------
Server listening on 5201
-----------------------------------------------------------
redpanda2:~$ sudo apt update; sudo apt install iperf3
redpanda2:~$ iperf3 -c redpanda1 -p 5201 -t 300
Connecting to host redpanda1, port 5201
[ ID] Interval Transfer Bitrate Retr Cwnd
[ 5] 0.00-1.00 sec 1.11 GBytes 9.57 Gbits/sec 0 1.64
MBytes
[ 5] 1.00-2.00 sec 1.11 GBytes 9.53 Gbits/sec 0 1.64
MBytes
[ 5] 2.00-3.00 sec 1.11 GBytes 9.53 Gbits/sec 0 1.64
MBytes
[ 5] 3.00-4.00 sec 1.11 GBytes 9.53 Gbits/sec 0 1.72
MBytes
[ 5] 4.00-5.00 sec 1.11 GBytes 9.53 Gbits/sec 0 1.72
MBytes
...CPU and memory
Redpanda is designed to scale up to utilize all available hardware and scale out to distribute performance across multiple nodes. Topic partitions are the unit of parallelization in Redpanda. Adding partitions is how you scale to meet workload demands.
Redpanda implements a thread-per-core programming model through its use of the Seastar library. This allows Redpanda to pin each of its application threads to a CPU core to avoid context switching and blocking, significantly improving processing performance and efficiency. Redpanda can handle approximately one GB/sec of writes for each core, depending on the workload. Since NVMe disks can have a sustained write speed of over one GB/sec, it takes two cores to saturate a single NVMe disk. A general recommendation is to have 100 MB/sec for each core.
Redpanda is basically a distributed transaction log with well-understood access patterns. It appends data to the end of log files and sequentially reads data from log files. Because Redpanda understands its own access patterns better than the operating system does, Redpanda chooses to bypass the Linux page cache and manages its own memory and disk I/O. This gives Redpanda complete control over the underlying hardware to optimize I/O performance, deliver predictable tail latencies, and minimize its memory footprint. A minimum of 2 GB of memory for each core is recommended, but more is better.
Storage
Your best storage solution for your workload depends on your performance and data retention requirements.
If high throughput and low latency is most important, then use locally attached NVMe SSD disks. This is also a good option in the cloud. Just remember that in the cloud, local disks are ephemeral, so data is wiped when an instance is restarted. An alternative in the cloud is to use SSD-backed object storage to persist data between instance restarts. Most cloud providers have options for guaranteeing throughput and provisioned IOPS performance of network-attached storage, although network-attached storage almost always exhibits slightly higher tail latencies than direct-attached storage.
For example, AWS io2 volumes offer up to 64,000 IOPS and 1,000 MB/sec throughput with single-digit millisecond latency. This is an expensive option, so if you can trade performance for cost, then AWS gp3 volumes are a good alternative. GCP has comparable options with high-end Extreme persistent disks and the lesser SSD persistent disks. Likewise, Azure has Ultra, Premium, and Standard persistent disk options for choosing the right balance of performance versus cost.
Whichever option you choose, benchmark Redpanda’s underlying storage for read and write performance, at least from an I/O perspective. Fio is a good tool for replicating Redpanda’s sequential write pattern and load. The following example shows how to run fio on a Debian-based server:
| Ensure that the fio job runs against the chosen block device. By default, fio operates in the local directory. |
$ sudo apt -y update; sudo apt -y install fio
$ cd /var/lib/redpanda/data
$ sudo cat > fio-seq-write.job << EOF
[global]
name=fio-seq-write
filename=fio-seq-write
rw=write
bs=16K
direct=1
numjobs=4
group_reporting
time_based
runtime=300 # 5 minute runtime
[file1]
size=10G
ioengine=libaio
iodepth=16
EOF
$ sudo fio fio-seq-write.jobKey performance metrics:
-
IOPS = Input and output operations per second. IOPS represents how many sequential write operations per second the volume can handle.
-
BW = Average bandwidth measured in MB per second. Bandwidth divided by the write block size (for example, bs=16K) is the IOPS.
-
slat = Submission latency. The time in microseconds to submit the I/O to the kernel.
-
clat = Completion latency. The time in microseconds after slat until the device has completed the I/O.
-
lat = Overall latency in microseconds.
-
clat percentiles = Completion tail latency. Pay particular attention to p90 and above. This is a good indication of whether the volume can deliver predictable, consistent performance.
Data retention
Retention properties control how long messages are kept on disk before they’re deleted or compacted. You can configure data retention until message age or aggregate message size in the topic is exceeded. Setting retention properties (at the topic level or the cluster level) is the best way to prevent old messages from accumulating on disk to the point that the disk becomes full.
See also: Configure message retention and Set retention limits
Tiered Storage
Redpanda Tiered Storage enables multi-tiered object storage. It archives log segments to object storage in near real time while maintaining the ability for brokers to fetch and serve these archived segments to slow consumers transparently and without any client configuration.
With only local storage, data retention is limited to the provisioned capacity: you must provision more nodes to increase capacity. Adding nodes is expensive, because you’re forced to overprovision infrastructure regardless of whether you need the additional compute power. In most cases, overprovisioning leads to underutilization and higher operational costs.
Tiered Storage can be combined with local storage to provide long-term data retention and disaster recovery on a per-topic basis. Retention properties work the same for Tiered Storage topics and local storage topics. Data is retained in the cloud until it reaches the configured time or size limit.
Ideally, a cluster should be sized such that the cluster’s local storage can service the majority of its consumers within a normal amount of lag, with Tiered Storage used to service any slow readers (for example, in the event of some downstream failure).
When Tiered Storage is enabled on a topic, it copies closed log segments to the configured storage bucket or container. Log segments are closed when the value of log_segment_size has been reached, so a topic’s object store lags behind the local copy. You can set an idle timeout to force Redpanda to periodically archive the contents of open log segments to object storage. This is useful if a topic’s write rate is low and log segments are kept open for long periods of time.
Adjusting how much data the object store lags behind the local copy allows Redpanda to meet stricter recovery point-in-time objectives. This is encapsulated in the Kafka API, so clients can continue to produce and consume data from Redpanda in the same way. Consumers that keep up with producers continue to read from local storage and are subject to the local data retention policy. Consumers that want to read from older offsets do so with the same consumer API, and Redpanda handles fetching the necessary log segments from object storage.
See also: Tiered Storage
Production settings
Before running performance benchmark testing, set Redpanda into production mode and run the autotuner tool (rpk redpanda tune all) on every node. This enables the necessary hardware optimizations and ensures that kernel parameters are set correctly.
See also: Set Redpanda production mode and autotuner reference
Open Messaging Benchmark
Performance benchmarking a distributed system like Redpanda requires careful orchestration, instrumentation, and measurement. Every cluster destined for production should be subject to performance benchmarking for validation and confidence in the setup.
The Open Messaging Benchmark (OMB) framework simplifies the process. OMB contains extensible tests that replicate realworld stress on a streaming platform to measure throughput and latency over given time periods. OMB can verify that a Redpanda cluster, deployed in your own data center or in the cloud, is sized appropriately for your use case.
See also: Redpanda Benchmarks
