Use Tiered Storage
|
This feature requires an enterprise license. To get a trial license key or extend your trial period, generate a new trial license key. To purchase a license, contact Redpanda Sales. If Redpanda has enterprise features enabled and it cannot find a valid license, restrictions apply. |
Tiered Storage helps to lower storage costs by offloading log segments to object storage. You can specify the amount of storage you want to retain in local storage. You don’t need to specify which log segments you want to move, because Redpanda moves them automatically based on cluster-level configuration properties. Tiered Storage indexes where data is offloaded, so it can look up the data when you need it.
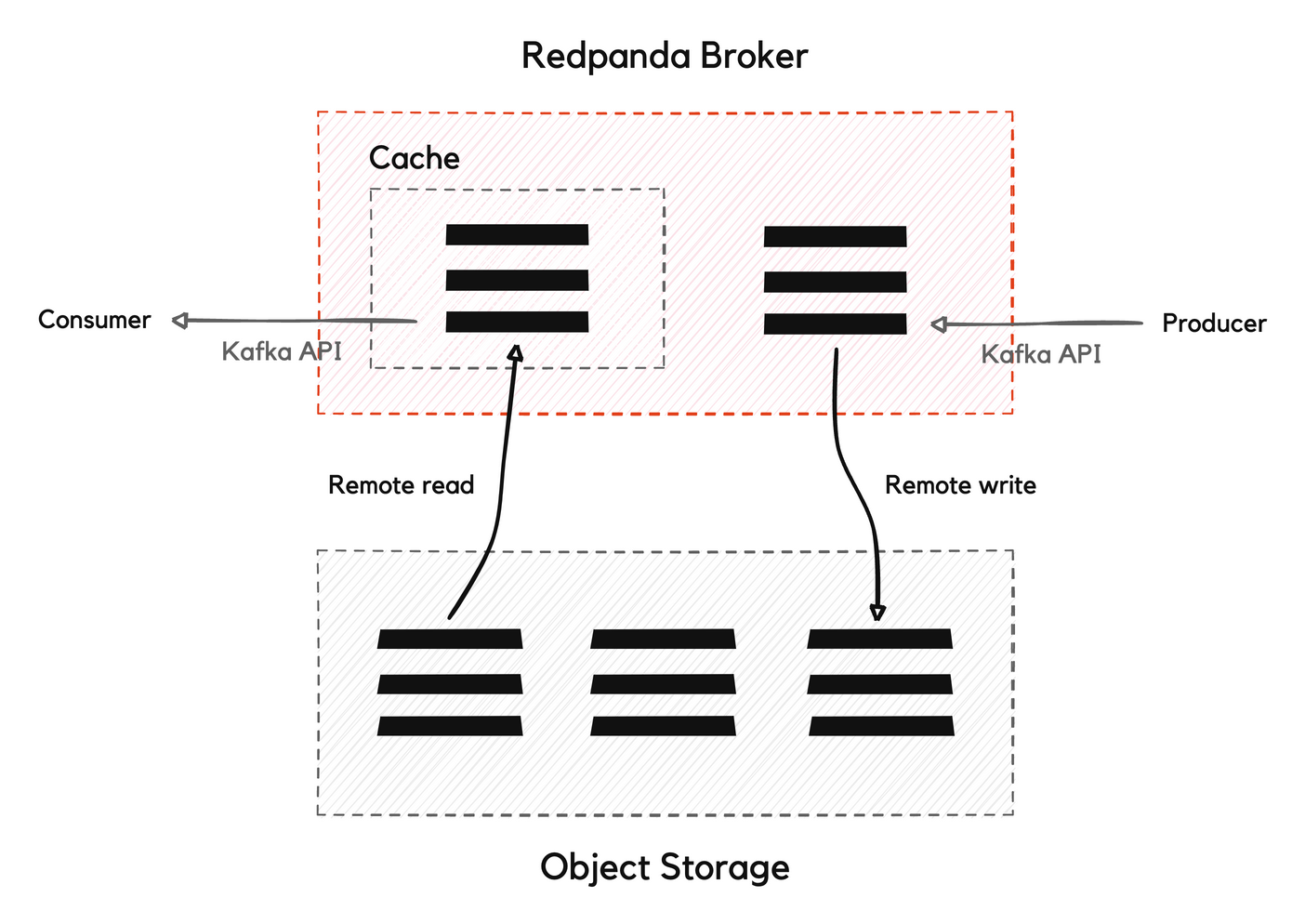
The following image illustrates the Tiered Storage architecture: remote write uploads data from Redpanda to object storage, and remote read fetches data from object storage to Redpanda.
Prerequisites
This feature requires an enterprise license. To get a trial license key or extend your trial period, generate a new trial license key. To purchase a license, contact Redpanda Sales.
If Redpanda has enterprise features enabled and it cannot find a valid license, restrictions apply.
To check if you already have a license key applied to your cluster:
rpk cluster license infoLimitations
-
Migrating topics from one object storage provider to another is not supported.
-
Migrating topics from one bucket or container to another is not supported.
-
Multi-region buckets or containers are not supported.
| Redpanda Data recommends that you do not re-enable Tiered Storage after previously enabling and disabling it. Re-enabling Tiered Storage can result in inconsistent data and data gaps in Tiered Storage for a topic. |
Set up Tiered Storage
To set up Tiered Storage:
-
Enable Tiered Storage. You can enable Tiered Storage for the cluster (all topics) or for specific topics.
Configure object storage
Redpanda natively supports Tiered Storage with Amazon Simple Storage Service (S3), Google Cloud Storage (GCS, which uses the Google Cloud Platform S3 API), and Microsoft Azure Blob Storage (ABS) and Azure Data Lake Storage (ADLS).
-
Amazon S3
-
Google Cloud Storage
-
Microsoft ABS/ADLS
| If deploying Redpanda on an AWS Auto-Scaling group (ASG), keep in mind that the ASG controller terminates nodes and spins up replacements if the nodes saturate and are unable to heartbeat the controller (based on the EC2 health check). For more information, see the AWS documentation. Redpanda recommends deploying on Linux or Kubernetes. For more information, see Deploy Redpanda. |
Configure access to Amazon S3 with either an IAM role attached to the instance, with access keys, or with customer-managed keys.
|
If you need to manage and store encryption keys separately from your cloud provider, you can configure access to an AWS S3 bucket that Redpanda Tiered Storage uses to leverage your AWS KMS key (SSE-KMS) instead of the default AWS S3-managed key (SSE-S3). This option enables you to segregate data from different teams or departments and remove that data at will by removing the encryption keys. |
Configure access with an IAM role
-
Configure an IAM role.
-
Run the
rpk cluster config editcommand, then edit the following required properties:cloud_storage_enabled: true cloud_storage_credentials_source: aws_instance_metadata cloud_storage_region: <region> cloud_storage_bucket: <redpanda-bucket-name>Replace
<placeholders>with your own values.
Do not set an object storage property to an empty string "" or to null as a way to reset it to its default value. To reset a property to its default value, run rpk cluster config force-reset <config-name> or remove that line from the cluster configuration with rpk cluster config edit.
|
Configure access with access keys
-
Grant a user the following permissions to read and create objects on the bucket to be used with the cluster (or on all buckets):
GetObject,DeleteObject,PutObject,PutObjectTagging,ListBucket. -
Copy the access key and secret key for the
cloud_storage_access_keyandcloud_storage_secret_keycluster properties. -
Run the
rpk cluster config editcommand, then edit the following required properties:cloud_storage_enabled: true cloud_storage_access_key: <access_key> cloud_storage_secret_key: <secret_key> cloud_storage_region: <region> cloud_storage_bucket: <redpanda-bucket-name>Replace
<placeholders>with your own values.Do not set an object storage property to an empty string ""or tonullas a way to reset it to its default value. To reset a property to its default value, runrpk cluster config force-reset <config-name>or remove that line from the cluster configuration withrpk cluster config edit.
Configure access with an AWS KMS key
When there are strict data compliance requirements and you must manage and store encryption keys separate from your cloud provider, you can configure an Amazon S3 bucket that Tiered Storage can use to leverage your customer-provided key (SSE-KMS) instead of the default AWS-managed key (SSE-S3).
To convert an existing S3 bucket and its contents, you must:
-
Create a new KMS key.
-
Configure the S3 bucket to use the new KMS key.
-
(Optional) Re-encrypt existing objects to use the new KMS key.
|
You cannot configure a cloud provider-managed encryption key at the topic level. For topic-level control, each CLI Get or Put for a partition must use the correct key as configured on the topic. |
Prerequisites
-
The user configuring S3 bucket encryption must be assigned the Key admin permission. Without this permission, the user is unable to re-encrypt existing bucket objects to use the KMS key.
-
The S3 bucket must be assigned the Key user permission. Without this permission, Redpanda is unable to write new objects to Tiered Storage.
-
If you intend to retroactively re-encrypt existing data with the new KMS key, store the ARN identifier of the key upon creation. It is required for AWS CLI commands.
To create a new KMS key in the AWS Console:
-
In AWS Console, search for “Key Management Service”.
-
Click Create a key.
-
On the Configure key page, select the Symmetric key type, then select Encrypt and decrypt.
-
Click the Advanced options tab and configure Key material origin and Regionality as needed. For example, if you are using Remote Read Replicas or have Redpanda spanning across regions, select Multi-Region key.
-
Click Next.
-
On the Add labels page, specify an alias name and description for the key. Do not include sensitive information in these fields.
-
Click Next.
-
On the Define key administrative permissions page, specify a user who can administer this key through the KMS API.
-
Click Next.
-
On the Define key usage permissions page, assign the S3 bucket as a Key user. This is required for the S3 bucket to encrypt and decrypt.
-
Click Next.
-
Review your KMS key configuration and click Finish.
For more information, see the AWS documentation.
To configure the S3 bucket to use the new KMS key (and reduce KMS costs through caching):
-
In AWS Console, search for "S3".
-
Select the bucket used by Redpanda.
-
Click the Properties tab.
-
In Default encryption, click Edit.
-
For Encryption type, select “Server-side encryption with AWS Key Management Service keys (SSE-KMS)”.
-
Locate and select your AWS KMS key ARN identifier.
-
Click Save changes.
(Optional) To re-encrypt existing data using the new KMS key:
Existing data in your S3 bucket continues to be read using the AWS-managed key, while new objects are encrypted using the new KMS key. If you wish to re-encrypt all S3 bucket data to use the KMS key, run:
aws s3 cp s3://{BUCKET_NAME}/ s3://{BUCKET_NAME}/ --recursive --sse-kms-key-id {KMS_KEY_ARN} --sse aws:kmsFor more information, see the AWS documentation.
Configure access to Google Cloud Storage with either an IAM role attached to the instance, with access keys, or with customer-managed keys.
Configure access with an IAM role
-
Configure an IAM role.
-
Run the
rpk cluster config editcommand, then edit the following required properties:cloud_storage_enabled: true cloud_storage_api_endpoint: storage.googleapis.com cloud_storage_credentials_source: gcp_instance_metadata cloud_storage_region: <region> cloud_storage_bucket: <redpanda-bucket-name>Replace
<placeholders>with your own values.Do not set an object storage property to an empty string ""or tonullas a way to reset it to its default value. To reset a property to its default value, runrpk cluster config force-reset <config-name>or remove that line from the cluster configuration withrpk cluster config edit.
Configure access with access keys
-
Choose a uniform access control when you create the bucket.
-
Use a Google-managed encryption key.
-
Set a default project.
-
Create a service user with HMAC keys and copy the access key and secret key for the
cloud_storage_access_keyandcloud_storage_secret_keycluster properties. -
Run the
rpk cluster config editcommand, then edit the following required properties:cloud_storage_enabled: true cloud_storage_api_endpoint: storage.googleapis.com cloud_storage_access_key: <access_key> cloud_storage_secret_key: <secret_key> cloud_storage_bucket: <redpanda-bucket-name> cloud_storage_region: <region>Replace
<placeholders>with your own values.Do not set an object storage property to an empty string ""or tonullas a way to reset it to its default value. To reset a property to its default value, runrpk cluster config force-reset <config-name>or remove that line from the cluster configuration withrpk cluster config edit.
Configure access with a KMS key
To configure the Google Cloud bucket used by Redpanda Tiered Storage to leverage a customer-managed key using the Cloud Key Management Service API instead of the default Google-managed key, you must:
-
Create a KMS key.
-
Configure the bucket to use the KMS key.
-
Optionally, re-encrypt existing data with the new KMS key.
To manage Google Cloud KMS using the command line, first install or upgrade to the latest version of Google Cloud CLI.
To create a KMS key:
-
In Google Cloud Console, search for "Cloud Key Managment Service API". Click Enable if the service is not already enabled.
-
Using the Google Cloud CLI, create a new keyring in the region where the bucket used by Redpanda is located. Note that region is case sensitive.
gcloud kms keyrings create "redpanda-keyring" --location="{REGION}" -
Create a new key for the keyring in the same region as the bucket:
gcloud kms keys create "redpanda-key" \ --location="{REGION}" \ --keyring="redpanda-keyring" \ --purpose="encryption" -
Get the key identifier:
gcloud kms keys list \ --location="REGION" \ --keyring="redpanda-keyring"The result should look like the following. Be sure to store the name, as this is used to assign and manage the key. Use this as the {KEY_RESOURCE} placeholder in subsequent commands.
NAME PURPOSE ALGORITHM PROTECTION_LEVEL LABELS PRIMARY_ID PRIMARY_STATE projects/{PROJECT_NAME}/locations/us/keyRings/redpanda-keyring/cryptoKeys/redpanda-key ENCRYPT_DECRYPT GOOGLE_SYMMETRIC_ENCRYPTION SOFTWARE 1 ENABLED
To configure the GCP bucket to use the KMS key:
-
Assign the key to a service agent:
gcloud storage service-agent \ --project={PROJECT_ID_STORING_OBJECTS} \ --authorize-cmek={KEY_RESOURCE} -
Set the bucket default encryption key to the KMS key:
gcloud storage buckets update gs://{BUCKET_NAME} \ --default-encryption-key={KEY_RESOURCE}
(Optional) To re-encrypt existing data using the new KMS key:
Existing data in the bucket continues to be read using the Google-managed key, while new objects are encrypted using the new KMS key. If you wish to re-encrypt all data in the bucket to use the KMS key, run:
gcloud storage objects update gs://{BUCKET_NAME}/ --recursive \
--encryption-key={KEY_RESOURCE}
Starting in release 23.2.8, Redpanda supports storage accounts configured for ADLS Gen2 with hierarchical namespaces enabled. For hierarchical namespaces created with a custom endpoint, set cloud_storage_azure_adls_endpoint and cloud_storage_azure_adls_port. If you haven’t configured custom endpoints in Azure, there’s no need to edit these properties.
|
Configure access with managed identities
-
Configure an Azure managed identity.
Note the minimum set of permissions required for Tiered Storage:
-
Microsoft.Storage/storageAccounts/blobServices/containers/blobs/delete
-
Microsoft.Storage/storageAccounts/blobServices/containers/blobs/read
-
Microsoft.Storage/storageAccounts/blobServices/containers/blobs/write
-
Microsoft.Storage/storageAccounts/blobServices/containers/blobs/add/action
-
Microsoft.Storage/storageAccounts/fileServices/fileShares/files/write
-
Microsoft.Storage/storageAccounts/fileServices/writeFileBackupSemantics/action
-
-
Run the
rpk cluster config editcommand, then edit the following required properties:cloud_storage_enabled: true cloud_storage_credentials_source: azure_vm_instance_metadata cloud_storage_azure_managed_identity_id: <managed-identity-client-id> cloud_storage_azure_storage_account: <storage-account-name> cloud_storage_azure_container: <container-name>Replace
<placeholders>with your own values.
Configure access with account access keys
-
Copy an account access key for the Azure container you want Redpanda to use and enter it in the
cloud_storage_azure_shared_keyproperty. For information on how to view your account access keys, see the Azure documentation. -
Run the
rpk cluster config editcommand, then edit the following required properties:cloud_storage_enabled: true cloud_storage_azure_shared_key: <azure_account_access_key> cloud_storage_azure_storage_account: <azure_account_name> cloud_storage_azure_container: <redpanda_container_name>Replace
<placeholders>with your own values.For information about how to grant access from an internet IP range (if you need to open additional routes/ports between your broker nodes and ABS/ADLS; for example, in a hybrid cloud deployment), see the Microsoft documentation.
For information about Shared Key authentication, see the Microsoft documentation.
Do not set an object storage property to an empty string ""or tonullas a way to reset it to its default value. To reset a property to its default value, runrpk cluster config force-reset <config-name>or remove that line from the cluster configuration withrpk cluster config edit.
For additional properties, see Tiered Storage configuration properties.
Enable Tiered Storage
-
To enable Tiered Storage, set
cloud_storage_enabledtotrue. -
Configure topics for Tiered Storage. You can configure either all topics in a cluster or only specific topics.
When you enable Tiered Storage on a topic already containing data, Redpanda uploads any existing data in that topic on local storage to the object store bucket. It will start from the earliest offset available on local disk. Redpanda strongly recommends that you avoid repeatedly toggling remote write on and off, because this can result in inconsistent data and data gaps in Tiered Storage for a topic.
Enable Tiered Storage for a cluster
To enable Tiered Storage for a cluster (in addition to setting cloud_storage_enabled to true), set the following cluster-level properties to true:
When you enable Tiered Storage for a cluster, you enable it for all existing topics in the cluster. You must restart your cluster after enabling Tiered Storage.
cloud_storage_enable_remote_write and cloud_storage_enable_remote_read act as creation-time defaults only for topics with redpanda.storage.mode=unset. They have no effect on topics where redpanda.storage.mode is explicitly set to local, tiered, or cloud. To apply a default storage mode to all new topics, use the default_redpanda_storage_mode cluster property instead.
|
Enable Tiered Storage for specific topics
Starting in Redpanda v26.1, the recommended way to enable Tiered Storage for a topic is to set the redpanda.storage.mode topic property to tiered:
rpk topic create <topic_name> -c redpanda.storage.mode=tieredTo enable Tiered Storage on an existing topic that was created in local mode:
rpk topic alter-config <topic_name> --set redpanda.storage.mode=tieredWhen redpanda.storage.mode=tiered is set, Tiered Storage is fully enabled for the topic. The redpanda.remote.read and redpanda.remote.write topic properties have no effect on a topic’s storage when redpanda.storage.mode is set to any value other than unset.
Configure Tiered Storage using legacy topic properties
For topics with redpanda.storage.mode=unset (the default when default_redpanda_storage_mode is not configured), Tiered Storage is controlled by the redpanda.remote.read and redpanda.remote.write topic properties:
-
redpanda.remote.write: Uploads data from Redpanda to object storage. -
redpanda.remote.read: Fetches data from object storage to Redpanda.
For example, to create a topic using the legacy properties when the storage mode is unset:
rpk topic create <topic_name> -c redpanda.remote.read=true -c redpanda.remote.write=trueTo enable Tiered Storage on an existing topic where the storage mode is unset:
rpk topic alter-config <topic_name> --set redpanda.remote.read=true --set redpanda.remote.write=trueFor newly-created unset topics, the cluster-level cloud_storage_enable_remote_write and cloud_storage_enable_remote_read properties dictate the topic-level properties redpanda.remote.write and redpanda.remote.read at topic creation time, respectively. Altering the cluster properties has no effect on existing topics, only newly-created ones. To alter the permissions for existing topics, you can set these topic properties directly. For example, redpanda.remote.write=false to disable uploads for a specific topic.
Tiered Storage topic-level properties:
| Property | Description |
|---|---|
|
Uploads data from Redpanda to object storage. For topics with |
|
Fetches data from object storage to Redpanda. For topics with |
|
Recovers or reproduces a topic from object storage. Use this property during topic creation. It does not apply to existing topics. |
|
When set to For Tiered Storage topics, the topic must not be a Remote Read Replica topic. When set to Default is |
The following tables show outcomes for combinations of cluster-level and topic-level configurations for topics with redpanda.storage.mode=unset at topic creation time:
Cluster-level configuration with cloud_storage_enable_remote_write |
Topic-level configuration with redpanda.remote.write |
Outcome: whether remote write is enabled or disabled on the topic |
|---|---|---|
|
Not set |
Enabled |
|
|
Disabled |
|
|
Enabled |
|
Not set |
Disabled |
|
|
Disabled |
|
|
Enabled |
Cluster-level configuration with cloud_storage_enable_remote_read |
Topic-level configuration with redpanda.remote.read |
Outcome: whether remote read is enabled or disabled on the topic |
|---|---|---|
|
Not set |
Enabled |
|
|
Disabled |
|
|
Enabled |
|
Not set |
Disabled |
|
|
Disabled |
|
|
Enabled |
Choose a Tiered Storage version
Starting in Redpanda v26.2, Tiered Storage is available in two versions:
-
Tiered Storage v1 (
tiered_v1) is the original implementation and remains the default. -
Tiered Storage v2 (
tiered_v2) (beta) is a new implementation that adds full compaction support, including tombstone removal, for topics stored in object storage.
| Tiered Storage v2 is a beta feature. It is not supported for production deployments. Beta features are available for users to test and provide feedback. |
You enable both versions the same way, by setting redpanda.storage.mode=tiered on a topic, and the storage mode of a topic displays as tiered for both. The version used by each topic is reported by the read-only redpanda.storage.mode.impl topic property.
Differences between Tiered Storage v1 and v2
The two versions differ in how they compact topics with a compact cleanup policy:
| Tiered Storage v1 | Tiered Storage v2 | |
|---|---|---|
Compacted data |
Compaction runs on local data only. Data that has already been uploaded to object storage is not compacted, so duplicate keys can remain in object storage indefinitely. |
Compaction runs on the data in object storage, so the entire partition is compacted. |
Compaction window |
Compaction is limited to a small window of data, and only duplicate keys that fall within the same window are removed. |
Full compaction: eventually only the latest value for each key is retained across the entire partition. |
Tombstone removal |
Not supported. Tombstone records are not removed by compaction. |
Supported. Tombstone records are removed after the retention period configured by |
Select a Tiered Storage version
The tiered value of the redpanda.storage.mode topic property is an alias. When a topic is created, it resolves to the version selected by the default_redpanda_storage_mode_tiered_impl cluster property, which defaults to tiered_v1. To make all new tiered topics use Tiered Storage v2:
rpk cluster config set default_redpanda_storage_mode_tiered_impl=tiered_v2To select the version explicitly for a single topic, regardless of the cluster-wide default, set both the redpanda.storage.mode and redpanda.storage.mode.impl properties when you create the topic:
rpk topic create <topic_name> -c redpanda.storage.mode=tiered -c redpanda.storage.mode.impl=tiered_v2The two values must agree: both tiered_v1 and tiered_v2 correspond to the tiered storage mode. You can set redpanda.storage.mode.impl on its own only when it matches the version selected by the cluster default.
To check which version an existing topic uses, run rpk topic describe <topic_name>. The redpanda.storage.mode property displays tiered for both versions, and the redpanda.storage.mode.impl property reports tiered_v1 or tiered_v2.
Tiered Storage v2 restrictions
-
You can create Tiered Storage v2 topics only after every broker in the cluster runs v26.2 or later. During a rolling upgrade, requests to create them are rejected. After the upgrade completes, no additional action is required.
-
Upgrading a cluster never changes the version of existing topics. Changing
default_redpanda_storage_mode_tiered_implaffects only topics created after the change. -
A topic cannot be converted between Tiered Storage v1 and v2. The
redpanda.storage.mode.implproperty is read-only and can be set only when the topic is created.
Set retention limits
Redpanda supports retention limits and compaction for topics using Tiered Storage. Set retention limits to purge topic data after it reaches a specified age or size.
Starting in Redpanda version 22.3, object storage is the default storage tier for all streaming data, and retention properties work the same for Tiered Storage topics and local storage topics. Data is retained in object storage until it reaches the configured time or size limit.
Data becomes eligible for deletion from object storage following retention.ms or retention.bytes. For example, if retention.bytes is set to 10 GiB, then every partition in the topic has a limit of 10 GiB in object storage. When retention.bytes is exceeded by data in object storage, the data in object storage is trimmed. If neither retention.ms nor retention.bytes is specified, then cluster-level defaults are used.
|
See also: Configure message retention and Space management
Compacted topics in Tiered Storage
When you set cleanup.policy for a topic to compact, nothing gets deleted from object storage based on retention settings. When set to compact,delete, compacted segments are deleted from object storage based on retention.ms and retention.bytes.
For compacted topics that use Tiered Storage v1, Redpanda compacts segments locally and re-uploads them to object storage. Redpanda initially uploads all uncompacted segments. It then re-uploads the segments with compaction applied. Because compaction runs on local data only, it’s likely that some segments in object storage are not compacted, but the Tiered Storage read path can manage this.
For compacted topics that use Tiered Storage v2, available starting in Redpanda v26.2, compaction runs on the data in object storage, so the entire partition is eventually compacted.
Manage local capacity for Tiered Storage topics
You can use properties to control retention of topic data in local storage. With Tiered Storage enabled, data in local storage expires after the topic-level properties retention.local.target.ms or retention.local.target.bytes. (These settings are equivalent to retention.ms and retention.bytes without Tiered Storage.)
You can also use the cluster-level properties retention_local_target_ms_default and retention_local_target_bytes_default. Settings can depend on the size of your drive, how many partitions you have, and how much data you keep for each partition.
When set, Redpanda keeps actively-used and sequential (next segment) data in local cache and targets to maintain this age of data in local storage. It purges data based on actual available local volume space, without forcing disk full situations when there is data skew.
At topic creation with Tiered Storage enabled:
-
If
retention.msorretention.bytesis set, Redpanda initializes theretention.local.target.*properties. -
If
retention.local.target.msorretention.local.target.bytesis set, Redpanda initializes themin(retention.bytes, retention.local.target.bytes)andmax(retention.ms, retention.local.target.ms)properties. -
If properties are not specified:
-
Starting in version 22.3, new topics use the default retention values of one day for local storage (
retention_local_target_ms_default) and seven days for all storage, including object storage (log_retention_ms). -
Upgraded topics retain their historical defaults of infinite retention.
-
After topic configuration, if Tiered Storage was disabled and must be enabled, or was enabled and must be disabled, Redpanda uses the local retention properties set for the topic. It is strongly recommended that you do not re-enable Tiered Storage after previously enabling and disabling it. Re-enabling Tiered Storage can result in inconsistent data and data gaps in Tiered Storage for a topic.
See also: Space management
View space usage
Use rpk cluster logdirs describe to get details about Tiered Storage space usage in both object storage and local disk. The directories for object storage start with remote://<bucket_name>. For example:
rpk cluster logdirs describe
BROKER DIR TOPIC PARTITION SIZE ERROR
0 /home/redpanda/var/node0/data monday 0 18406863
0 remote://data monday 0 60051220
1 /home/redpanda/var/node1/data monday 0 22859882
1 remote://data monday 0 60051220
2 /home/redpanda/var/node2/data monday 0 17169935
2 remote://data monday 0 60051220Integration with space utilization tools
Third-party tools that query space utilization from the Redpanda cluster might not handle remote:// entries properly. Redpanda space usage is reported from each broker, but object storage is shared between brokers. Third-party tools could over-count storage and show unexpectedly high disk usage for Tiered Storage topics. In this situation, you can disable output of remote:// entries by setting kafka_enable_describe_log_dirs_remote_storage to false.
Remote write
Remote write is the process that constantly uploads log segments to object storage. The process is created for each partition and runs on the leader broker of the partition. It only uploads the segments that contain offsets that are smaller than the last stable offset. This is the latest offset that the client can read.
To ensure all data is uploaded, you must enable remote write before any data is produced to the topic. If you enable remote write after data has been written to the topic, only the data that currently exists on disk based on local retention settings will be scheduled for uploading. Redpanda strongly recommends that you avoid repeatedly toggling remote write on and off, because this can result in inconsistent data and data gaps in Tiered Storage for a topic.
To enable Tiered Storage, use both remote write and remote read.
To create a topic with remote write enabled:
rpk topic create <topic_name> -c redpanda.remote.write=trueTo enable remote write on an existing topic:
rpk topic alter-config <topic_name> --set redpanda.remote.write=trueIf remote write is enabled, log segments are not deleted until they’re uploaded to object storage. Because of this, the log segments may exceed the configured retention period until they’re uploaded, so the topic might require more disk space. This prevents data loss if segments cannot be uploaded fast enough or if the retention period is very short.
To see the object storage status for a given topic:
rpk topic describe-storage <topic_name> --print-allSee the reference for a list of flags you can use to filter the command output.
|
A constant stream of data is necessary to build up the log segments and roll them into object storage. This upload process is asynchronous. You can monitor its status with the To see new log segments faster, you can edit the |
Idle timeout
You can configure Redpanda to start a remote write periodically. This is useful if the ingestion rate is low and the segments are kept open for long periods of time. You specify a number of seconds for the timeout, and if that time has passed since the previous write and the partition has new data, Redpanda starts a new write. This limits data loss in the event of catastrophic failure and adds a guarantee that you only lose the specified number of seconds of data.
Setting idle timeout to a very short interval can create a lot of small files, which can affect throughput. If you decide to set a value for idle timeout, start with 600 seconds, which prevents the creation of so many small files that throughput is affected when you recover the files.
Use the cloud_storage_segment_max_upload_interval_sec property to set the number of seconds for idle timeout. If this property is set to null, Redpanda uploads metadata to object storage, but the segment is not uploaded until it reaches the segment.bytes size.
Reconciliation
Reconciliation is a Redpanda process that monitors partitions and decides which partitions are uploaded on each broker to guarantee that data is uploaded only once. It runs periodically on every broker. It also balances the workload evenly between brokers.
| The broker uploading to object storage is always with the partition leader. Therefore, when partition leadership balancing occurs, Redpanda stops uploads to object storage from one broker and starts uploads on another broker. |
Upload backlog controller
Remote write uses a proportional derivative (PD) controller to minimize the backlog size for the write. The backlog consists of data that has not been uploaded to object storage but must be uploaded eventually.
The upload backlog controller prevents Redpanda from running out of disk space. If remote.write is set to true, Redpanda cannot evict log segments that have not been uploaded to object storage. If the remote write process cannot keep up with the amount of data that needs to be uploaded to object storage, the upload backlog controller increases priority for the upload process. The upload backlog controller measures the size of the upload periodically and tunes the priority of the remote write process.
Data archiving
If you only enable remote write on a topic, you have a simple backup to object storage that you can use for recovery. In the event of a data center failure, data corruption, or cluster migration, you can recover your archived data from the cloud back to your cluster.
Configure data archiving
Data archiving requires a Tiered Storage configuration.
To recover a topic from object storage, use single topic recovery.
| While performing topic recovery, avoid adding additional load (such as produces, consumes, lists or additional recovery operations) to the target cluster. Doing so could destabilize the recovery process and result in either an unsuccessful or corrupted recovered topic. |
Remote read
Remote read fetches data from object storage using the Kafka API.
Without Tiered Storage, when data is evicted locally, it is no longer available. If the consumer starts consuming the partition from the beginning, the first offset is the smallest offset available locally. However, when Tiered Storage is enabled with the redpanda.remote.read and redpanda.remote.write properties, data is always uploaded to object storage before it’s deleted. This guarantees that data is always available either locally or remotely.
When data is available remotely and Tiered Storage is enabled, clients can consume data, even if the data is no longer stored locally.
To create a topic with remote read enabled:
rpk topic create <topic_name> -c redpanda.remote.read=trueTo enable remote read on an existing topic:
rpk topic alter-config <topic_name> --set redpanda.remote.read=trueSee also: Topic Recovery, Remote Read Replicas
Pause and resume uploads
| Redpanda strongly recommends using pause and resume only under the guidance of Redpanda Support or a member of your account team. |
Starting in version 25.1, you can troubleshoot issues your cluster has interacting with object storage by pausing and resuming uploads. You can do this with no risk of data consistency or data loss. To pause or resume segment uploads to object storage, use the cloud_storage_enable_segment_uploads configuration property (default is true). This allows segment uploads to proceed after the pause completes and uploads resume.
While uploads are paused, data accumulates locally, which can lead to full disks if the pause is prolonged. If the disks fill, Redpanda throttles produce requests and rejects new Kafka produce requests to prevent data from being written. Additionally, this pauses object storage housekeeping, meaning segments are neither uploaded nor removed from object storage. However, it is still possible to consume data from object storage while uploads are paused.
When you set cloud_storage_enable_segment_uploads to false, all in-flight segment uploads complete, but no new segment uploads begin until the value is set back to true. During this pause, Tiered Storage enforces consistency by ensuring that no segment in local storage is deleted until it successfully uploads to object storage. This means that when uploads are resumed, no user intervention is needed, and no data gaps are created.
Use the redpanda_cloud_storage_paused_archivers metric to monitor the status of paused uploads. It displays a non-zero value whenever uploads are paused.
|
Do not use |
The following example shows a simple pause and resume with no gaps allowed:
rpk cluster config set cloud_storage_enable_segment_uploads false
# Segments are not uploaded to cloud storage, and cloud storage housekeeping is not running.
# The new data added to the topics with Tiered Storage is not deleted from disk
# because it can't be uploaded. The disks may fill up eventually.
# If the disks fill up, produce requests will be rejected.
...
rpk cluster config set cloud_storage_enable_segment_uploads true
# At this point the uploads should resume seamlessly and
# there should not be any data loss.For some applications, where the newest data is more valuable than historical data, data accumulation can be worse than data loss. In such cases, where you cannot afford to lose the most recently-produced data by rejecting produce requests after producers have filled the local disks during the period of paused uploads, there is a less safe pause and resume mechanism. This mechanism prioritizes the ability to receive new data over retaining data that cannot be uploaded when disks are full:
-
Set the
cloud_storage_enable_remote_allow_gapscluster configuration property totrue. This allows for gaps in the logs of all Tiered Storage topics in the cluster.
When you pause uploads and set one of these properties to true, there may be gaps in the range of offsets stored in object storage. You can seamlessly resume uploads by setting *allow_gaps to true at either the cluster or topic level. If set to false, disk space could be depleted and produce requests would be throttled.
The following example shows how to pause and resume Tiered Storage uploads while allowing for gaps:
rpk cluster config set cloud_storage_enable_segment_uploads false
# Segment uploads are paused and cloud storage housekeeping is not running.
# New data is stored on the local volume, which may overflow.
# To avoid overflow when allowing gaps in the log.
# In this example, data that is not uploaded to cloud storage may be
# deleted if a disk fills before uploads are resumed.
...
rpk cluster config set cloud_storage_enable_segment_uploads true
# Uploads are resumed but there could be gaps in the offsets.
# Wait until you see that the `redpanda_cloud_storage_paused_archivers`
# metric is equal to zero, indicating that uploads have resumed.Caching
When a consumer fetches an offset range that isn’t available locally in the Redpanda data directory, Redpanda downloads remote segments from object storage. These downloaded segments are stored in the object storage cache.
Change the cache directory
By default, the cache directory is created in Redpanda’s data directory, but it can be placed anywhere in the system. For example, you might want to put the cache directory on a dedicated drive with cheaper storage. Use the cloud_storage_cache_directory broker property to specify a different location for the cache directory. You must specify the full path.
Set a maximum cache size
To ensure that the cache does not grow uncontrollably, which could lead to performance issues or disk space exhaustion, you can control the maximum size of the cache.
Redpanda checks the cache periodically according to the interval set in cloud_storage_cache_check_interval_ms. If the size of the stored data exceeds the configured limit, the eviction process starts. This process removes segments that haven’t been accessed recently until the cache size drops to the target level.
Related properties:
Recommendation: By default, cloud_storage_cache_size_percent is tuned for a shared disk configuration. If you are using a dedicated cache disk, consider increasing this value.
Cache trimming
Cache trimming helps to balance optimal cache use with the need to avoid blocking reads due to a full cache. The trimming process is triggered when the cache exceeds certain thresholds relative to the maximum cache size.
Related properties:
Recommendations:
-
A threshold of 70% is recommended for most use cases. This percentage helps balance optimal cache use and ensures the cache has enough free space to handle sudden spikes in data without blocking reads. For example, setting
cloud_storage_cache_trim_threshold_percent_sizeto 80% means that the cache trimming process starts when the cache takes up 80% of the maximum cache size. -
Monitor the behavior of your cache and the performance of your Redpanda cluster. If reads are taking longer than expected or if you encounter timeout errors, your cache may be filling up too quickly. In these cases, consider lowering the thresholds to trigger trimming sooner.
| The lower you set the threshold, the earlier the trimming starts, but it can also waste cache space. A higher threshold uses more cache space efficiently, but it risks blocking reads if the cache fills up too quickly. Adjust the settings based on your workload and monitor the cache performance to find the right balance for your environment. |
Chunk remote segments
To support more concurrent consumers of historical data with less local storage, Redpanda can download small chunks of remote segments to the cache directory. For example, when a client fetch request spans a subsection of a 1 GiB segment, instead of downloading the entire 1 GiB segment, Redpanda can download 16 MiB chunks that contain just enough data required to fulfill the fetch request. Use the cloud_storage_cache_chunk_size property to define the size of the chunks.
The paths on disk to a chunk are structured as p_chunks/{chunk_start_offset}, where p is the original path to the segment in the object storage cache. The _chunks/ subdirectory holds chunk files identified by the chunk start offset. These files can be reclaimed by the cache eviction process during the normal eviction path.
Chunk eviction strategies
Selecting an appropriate chunk eviction strategy helps manage cache space effectively. A chunk that isn’t shared with any data source can be evicted from the cache, so space is returned to disk. Use the cloud_storage_chunk_eviction_strategy property to change the eviction strategy. The strategies are:
-
eager(default): Evicts chunks that aren’t shared with other data sources. Eviction is fast, because no sorting is involved. -
capped: Evicts chunks until the number of hydrated chunks is below or equal to the maximum hydrated chunks at a time. This limit is for each segment and calculated usingcloud_storage_hydrated_chunks_per_segment_ratioby the remote segment. Eviction is fastest, because no sorting is involved, and the process stops after the cap is reached. -
predictive: Uses statistics from readers to determine which chunks to evict. Chunks that aren’t in use are sorted by the count of readers that will use the chunk in the future. The counts are populated by readers using the chunk data source. The chunks that are least expensive to re-hydrate are then evicted, taking into account the maximum hydrated chunk count. Eviction is slowest, because chunks are sorted before evicting them.
Recommendation: For general use, the eager strategy is recommended due to its speed. For workloads with specific access patterns, the predictive strategy may offer better cache efficiency.
Caching and chunking properties
Use the following cluster-level properties to set the maximum cache size, the cache check interval, and chunking qualities.
Edit them with the rpk cluster config edit command.
| Property | Description |
|---|---|
The time, in milliseconds, between cache checks. The size of the cache can grow quickly, so it’s important to have a small interval between checks. However, if the checks are too frequent, they consume a lot of resources. Default is 30000 ms (30 sec). |
|
The size of a chunk downloaded into object storage cache. Default is 16 MiB. |
|
The directory where the cache archive is stored. |
|
Maximum number of objects that may be held in the Tiered Storage cache. This applies simultaneously with |
|
Divide the object storage cache across the specified number of buckets. This only works for objects with randomized prefixes. The names are not changed when the value is set to zero. |
|
Maximum size (as a percentage) of the disk cache used by Tiered Storage. |
|
Maximum size (in bytes) of the disk cache used by Tiered Storage. |
|
Trigger cache trimming when the number of objects in the cache reaches this percentage relative to its maximum object count. If unset, the default behavior is to start trimming when the cache is full. |
|
Trigger cache trimming when the cache size reaches this percentage relative to its maximum capacity. If unset, the default behavior is to start trimming when the cache is full. |
|
The maximum number of concurrent tasks launched for traversing the directory structure during cache trimming. A higher number allows cache trimming to run faster but can cause latency spikes due to increased pressure on I/O subsystem and syscall threads. |
|
Strategy for evicting unused cache chunks, either |
|
Flag to turn off chunk-based reads and enable full-segment downloads. Default is false. |
|
The ratio of hydrated to non-hydrated chunks for each segment, where a current ratio above this value results in unused chunks being evicted. Default is 0.7. |
|
The threshold below which all chunks of a segment can be hydrated without eviction. If the number of chunks in a segment is below this threshold, the segment is small enough that all chunks in it can be hydrated at any given time. Default is 5. |
Retries and backoff
If the object storage provider replies with an error message that the server is busy, Redpanda retries the request. Redpanda may retry on other errors, depending on the object storage provider.
Redpanda always uses exponential backoff with cloud connections. You can configure the cloud_storage_initial_backoff_ms property to set the time used as an initial backoff interval in the exponential backoff algorithm to handle an error. Default is 100 ms.
Transport
Tiered Storage creates a connection pool for each CPU that limits simultaneous connections to the object storage provider. It also uses persistent HTTP connections with a configurable maximum idle time. A custom S3 client is used to send and receive data.
For normal usage, you do not need to configure the transport properties. The Redpanda defaults are sufficient, and the certificates used to connect to the object storage client are available through public key infrastructure. Redpanda detects the location of the CA certificates automatically.
Redpanda uses the following properties to configure transport.
Edit them with the rpk cluster config edit command.
| Property | Description |
|---|---|
The maximum number of connections to object storage on a broker for each CPU. Remote read and remote write share the same pool of connections. This means that if a connection is used to upload a segment, it cannot be used to download another segment. If this value is too small, some workloads might starve for connections, which results in delayed uploads and downloads. If this value is too large, Redpanda tries to upload a lot of files at the same time and might overwhelm the system. Default is 20. |
|
Timeout for segment upload. Redpanda retries the upload after the timeout. Default is 30000 ms. |
|
Timeout for manifest upload. Redpanda retries the upload after the timeout. Default is 10000 ms. |
|
The maximum idle time for persistent HTTP connections. This differs depending on the object storage provider. Default is 5000 ms, which is sufficient for most providers. |
|
The number of seconds for idle timeout. If this property is empty, Redpanda uploads metadata to the object storage, but the segment is not uploaded until it reaches the |
|
The public certificate used to validate the TLS connection to object storage. If this is empty, Redpanda uses your operating system’s CA cert pool. |
Object storage housekeeping
To improve performance and scalability, Redpanda performs object storage housekeeping when the system is idle. This housekeeping includes adjacent segment merging, which analyzes the data layout of the partition in object storage. If it finds a run of small segments, it can merge and reupload the segment.
To determine when the system is idle for housekeeping, Redpanda constantly calculates object storage utilization using the moving average with a sliding window algorithm. The width of the sliding window is defined by the cloud_storage_idle_timeout_ms property, which has a default of 10 seconds. If the utilization (requests per second) drops below the threshold, then object storage is considered idle, and object storage housekeeping begins. The threshold is defined by the cloud_storage_idle_threshold_rps property, which has a default of one request per second. Object storage is considered idle if, during the last 10 seconds, there were 10 or less object storage API requests.
If the object storage API becomes active after housekeeping begins, then housekeeping is paused until it becomes idle again. If object storage is not idle for cloud_storage_housekeeping_interval_ms, then housekeeping is forced to run until it completes. This guarantees that all housekeeping jobs are run once for every cloud_storage_housekeeping_interval_ms.
See also: Space management
Adjacent segment merging
By default, and as part of this object storage housekeeping, Redpanda runs adjacent segment merging on all segments in object storage that are smaller than the threshold. Two properties control the behavior of cloud_storage_enable_segment_merging:
-
cloud_storage_segment_size_target: The desired segment size in object storage. The default segment size is the local segment size for the topic, which is controlled by thelog_segment_sizeconfiguration property and thesegment.bytestopic property. You can set thecloud_storage_segment_size_targetproperty to a value larger than the default segment size, but because this triggers a lot of segment re-uploads, it’s not recommended. -
cloud_storage_segment_size_min: The smallest segment size that Redpanda keeps in object storage. The default is 50% oflog_segment_size.
If the adjacent segment merging job finds a run of small segments, it can perform one of the following operations:
-
Merge and re-upload a segment with a size up to
cloud_storage_segment_size_target. -
Merge and re-upload a segment with a size less than
cloud_storage_segment_size_minif there are no other options (the run of small segments is followed by the large segment). -
Wait until new segments are added if the run is at the end of the partition.
Suppose the cloud_storage_segment_max_upload_interval_sec property is set and the partition contains a large number of small segments. For example, if sec is set to 10 minutes and the produce rate is 1 MiB per minute, then Redpanda uploads a new 10 MiB segment every 10 minutes. If adjacent segment merging is enabled and cloud_storage_segment_size_target is set to 500 MiB, then every 50 segments are re-uploaded as one large 500 MiB segment. This doubles the amount of data that Redpanda uploads to object storage, but it also reduces the memory footprint of the partition, which results in better scalability because 98% less memory is needed to keep information about the uploaded segment.
| Adjacent segment merging doesn’t work for compacted topics, because compacted segments are reuploaded after they’re compacted. The results are the same. |
Archived metadata
As data in object storage grows, the metadata for it grows. Starting in version 23.2, Redpanda archives older metadata in object storage to support efficient long-term data retention. Only metadata for recently-updated segments is kept in memory or on local disk, while the rest is safely stored in object storage and cached locally as needed. Archived metadata is loaded only when historical data is accessed. This allows Tiered Storage to handle partitions of virtually any size or retention length.
You can configure these object storage properties to control the metadata archiving behavior:
| Property | Description |
|---|---|
When the in-memory manifest size for a partition exceeds double this value, Redpanda triggers metadata spillover. The oldest metadata is packaged into a new spillover manifest and uploaded to object storage, after which the in-memory manifest is truncated. This process continues until the in-memory manifest size falls below the threshold. (Default: 65536 bytes) |
|
Triggers the upload of metadata to object storage when the number of segments in the spillover manifest exceeds this value. Redpanda recommends using this property only in testing scenarios, and |
|
Controls the amount of memory used by the cache for spilled manifests. (Default: 1048576 bytes) |
Tiered Storage configuration properties
The following list contains cluster-level configuration properties for Tiered Storage. Configure or verify the following properties before you use Tiered Storage:
| Property | Description |
|---|---|
Global property that enables Tiered Storage. Set to true to enable Tiered Storage. Default is false. |
|
Object storage region. Required for AWS and GCS. |
|
AWS or GCS bucket name. Required for AWS and GCS. |
|
AWS or GCS instance metadata. Required for AWS and GCS authentication with IAM roles. |
|
AWS or GCS access key. Required for AWS and GCS authentication with access keys. |
|
AWS or GCS secret key. Required for AWS and GCS authentication with access keys. |
|
AWS or GCS API endpoint.
|
|
Azure container name. Required for ABS/ADLS. |
|
Azure account name. Required for ABS/ADLS. |
|
Azure storage account access key. Required for ABS/ADLS. |
|
Maximum size (as a percentage) of the disk cache used by Tiered Storage. If both this property and |
|
Maximum size of the disk cache used by Tiered Storage. If both this property and |
|
Amount of disk space (as a percentage) reserved for general system overhead. Default is 20%. |
|
Target size (in bytes) of the log data. Default is not set (null). |
|
Target size (as a percentage) of the log data. Default is the amount of remaining disk space after deducting |
|
Allows the housekeeping process to remove data above the configured consumable retention. This means that data usage is allowed to expand to occupy more of the log data reservation. Default is false. |
|
Period at which disk usage is checked for disk pressure, where data is optionally trimmed to meet the target. Default is 30 seconds. |
In addition, you might want to change the following property for each broker:
| Property | Description |
|---|---|
The directory for the Tiered Storage cache. You must specify the full path. Default is: |
You may want to configure the following properties:
| Property | Description |
|---|---|
The maximum number of connections to object storage on a broker for each CPU. Remote read and remote write share the same pool of connections. This means that if a connection is used to upload a segment, it cannot be used to download another segment. If this value is too small, some workloads might starve for connections, which results in delayed uploads and downloads. If this value is too large, Redpanda tries to upload a lot of files at the same time and might overwhelm the system. Default is 20. |
|
The initial local retention size target for partitions of topics with Tiered Storage enabled. Default is null. |
|
The initial local retention time target for partitions of topics with Tiered Storage enabled. Default is null. |
|
The time, in milliseconds, for an initial backoff interval in the exponential backoff algorithm to handle an error. Default is 100 ms. |
|
Timeout for segment upload. Redpanda retries the upload after the timeout. Default is 30000 ms. |
|
Timeout for manifest upload. Redpanda retries the upload after the timeout. Default is 10000 ms. |
|
The maximum idle time for persistent HTTP connections. Differs depending on the object storage provider. Default is 5000 ms, which is sufficient for most providers. |
|
Sets the number of seconds for idle timeout. If this property is empty, Redpanda uploads metadata to the object storage, but the segment is not uploaded until it reaches the |
|
The time, in milliseconds, between cache checks. The size of the cache can grow quickly, so it’s important to have a small interval between checks, but if the checks are too frequent, they consume a lot of resources. Default is 30000 ms. |
|
The width of the sliding window for the moving average algorithm that calculates object storage utilization. Default is 10 seconds. |
|
The utilization threshold for object storage housekeeping. Object storage is considered idle if, during the last 10 seconds, there were 10 or less object storage API requests. Default is 1 request per second. |
|
Enables adjacent segment merging on all segments in object storage that are smaller than the threshold. Two properties control this behavior: |
|
The desired segment size in object storage. The default segment size is controlled by |
|
The smallest segment size in object storage that Redpanda keeps. Default is 50% of log segment size. |
Under normal circumstances, you should not need to configure the following tunable properties:
| Property | Description |
|---|---|
The recompute interval for the upload controller. Default is 60000 ms. |
|
The proportional coefficient for the upload controller. Default is -2. |
|
The derivative coefficient for the upload controller. Default is 0. |
|
The minimum number of I/O and CPU shares that the remote write process can use. Default is 100. |
|
The maximum number of I/O and CPU shares that the remote write process can use. Default is 1000. |
|
Disables TLS encryption. Set to true if TLS termination is done by the proxy, such as HAProxy. Default is false. |
|
Overrides the default API endpoint port. Default is 443. |
|
The public certificate used to validate the TLS connection to object storage. If this is empty, Redpanda uses your operating system’s CA cert pool. |
|
Deprecated. The interval, in milliseconds, to reconcile partitions that need to be uploaded. A long reconciliation interval can result in a delayed reaction to topic creation, topic deletion, or leadership rebalancing events. A short reconciliation interval guarantees that new partitions are picked up quickly, but the process uses more resources. Default is 10000 ms. |
