Manage Disk Space
It is important to manage the local disk space in Redpanda to ensure the stability of a cluster. If a node’s disk space reaches a critically-low level, then Redpanda blocks clients from writing new data. If a node runs out of disk space, then the Redpanda process terminates. This has a significant impact on performance, as client connections and topic data concentrates on fewer nodes.
Redpanda provides several ways to manage disk space, with varying degrees of flexibility and control over what data is removed from local disk and when.
-
Redpanda space management, when used with Tiered Storage, treats local disks as a cache.
-
For more granularity, you can configure topic-level retention policies to manage log cleanup based on partition size or age.
-
You can configure storage thresholds to alert you when disk space is running low.
-
You can enable Continuous Data Balancing to ensure well-balanced disk usage across the cluster.
-
You can create a ballast file to allow fast recovery from a full disk.
Configure message retention
By default, all topics on Redpanda Streaming clusters retain 24 hours of data on local disk, while Redpanda Cloud topics retain 6 hours of data. Redpanda makes use of dynamic space management strategies to save on disk space. If data is written fast enough, however, it’s possible to exhaust local disk space even when using Tiered Storage. Proper configuration of message retention properties for your use case can prevent this from happening.
Retention properties control the minimum length of time messages are kept on disk before they’re deleted or compacted. Setting message retention properties is the best way to prevent old messages from accumulating on disk to the point that the disk becomes full. You can configure retention properties to delete messages based on the following conditions:
-
Message age is exceeded.
-
Aggregate message size in the topic is exceeded.
-
A combination of message age and aggregate size, triggered when either is exceeded.
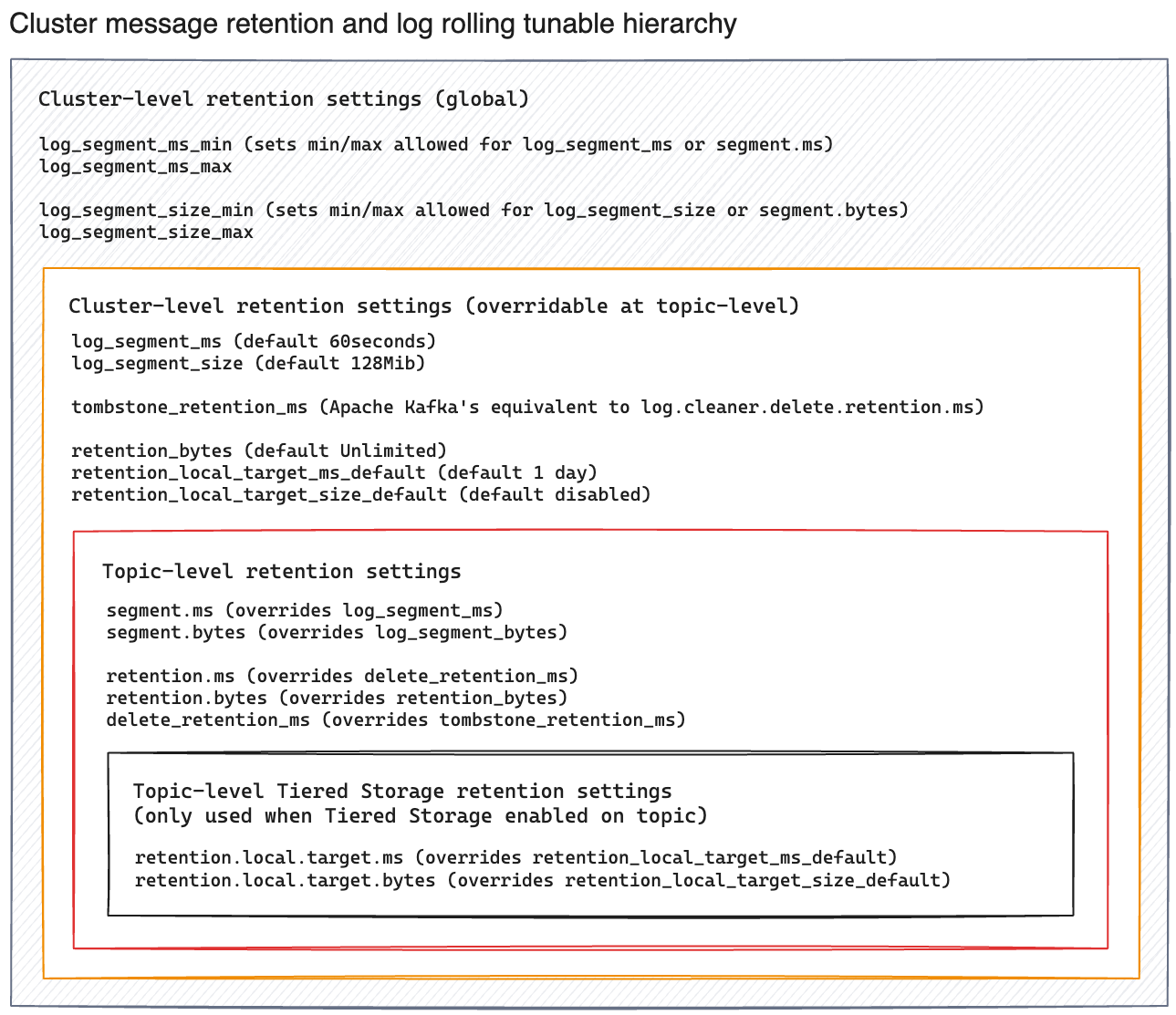
You may set retention properties at the topic level or the cluster level. If a value isn’t specified for the topic, then the topic uses the value for the cluster. Note that cluster-level property names use snake-case, while topic-level properties use dots.
Although retention policy is set at a cluster or topic level, it applies to each partition in a topic independently. Within a partition, only closed segments are eligible for deletion or compaction. When a time-based policy is set, all messages within the segment must exceed the set limit. For example, assume the retention.ms for a topic is 300,000 ms (5 minutes). If the segment.ms is 1,800,000ms (30 minutes) then messages will remain for a minimum of 30 minutes while the segment containing them remains open. In this scenario, five minutes after a new segment begins, the retention policy would trigger deletion of the closed segment.
|
Retention property |
Cluster level |
Topic level |
Time-based |
|
|
Size-based |
|
|
Time-based (with Tiered Storage enabled) |
|
|
Size-based (with Tiered Storage enabled) |
|
|
Segment lifetime |
|
|
Segment size |
|
|
Data expires from object storage following both retention.ms and retention.bytes. For example, if retention.bytes is set to 10 GiB, then every partition in the topic has a limit of 10 GiB storage. When retention.bytes is exceeded by data in object storage, the data in object storage is trimmed, even if retention.ms is not yet exceeded. With Tiered Storage enabled, data expires from local storage following retention.local.target.ms or retention.local.target.bytes.
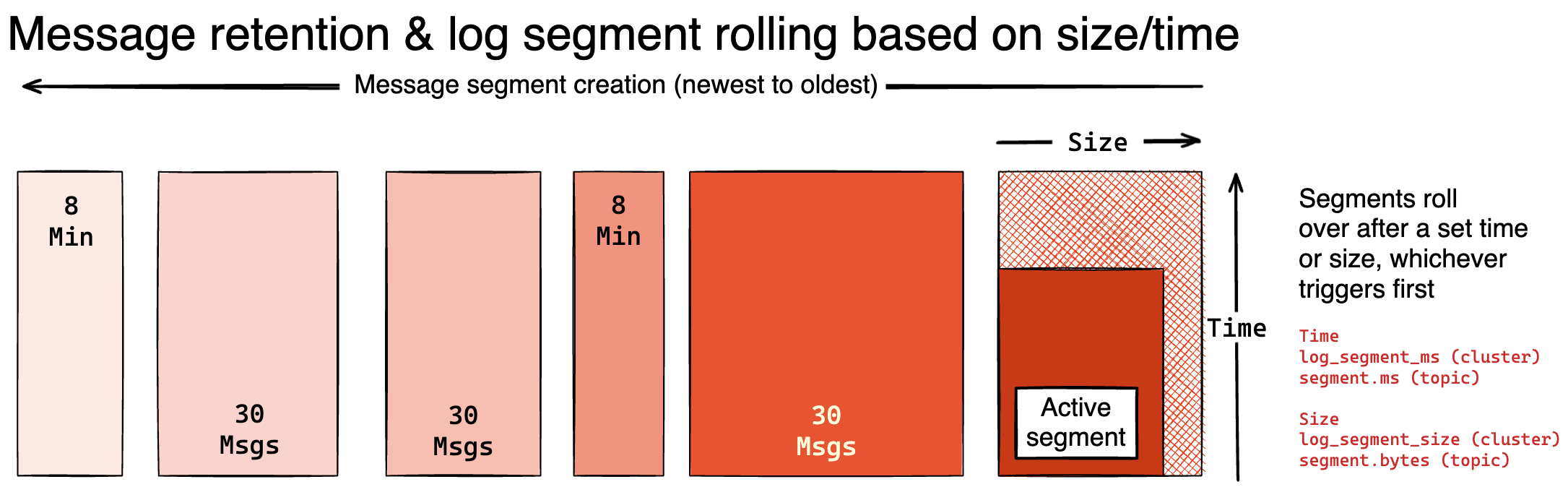
Retention policy functions by deleting or compacting closed segments. The segment lifetime and segment size configurations help ensure new segments are created regularly within each partition. This illustration shows how Redpanda creates new segments based on size and time. After the limit for a segment is reached, whether it’s size- or time-based, Redpanda closes the segment and begins filling a new segment. If the limits are set too high, the segment may fill available disk space before closing and therefore never become eligible for deletion or compaction. If the values are set too low, your partitions will have a large number of segments that must be checked each time deletion or compaction processes execute, having a potential adverse impact on system resource utilization.
| Both size-based and time-based retention policies are applied simultaneously. It’s possible for your size-based property to override your time-based property, or vice versa. For example, if your size-based property requires removing one segment, and your time-based property requires removing three segments, then three segments are removed. Size-based properties reclaim disk space as close as possible to the maximum size, without exceeding the limit. |
Redpanda runs a log cleanup process in the background to apply these policy settings. If you start to run out of disk space, adjusting your retention properties is an excellent way to reduce the amount of disk space used.
See also:
Set time-based retention
Redpanda enforces time-based retention to manage log segment deletion according to record timestamps. Messages are eligible for deletion when their age exceeds the value specified in log_retention_ms (the cluster-level property) or retention.ms (the topic-level property). Only closed segments are eligible for deletion and all messages in a closed segment must exceed the age limit before Redpanda considers the segment for cleanup. If retention.ms is not set at the topic level, the topic inherits the log_retention_ms setting.
Starting in v25.3, Redpanda validates timestamps using the properties log_message_timestamp_before_max_ms and log_message_timestamp_after_max_ms. These settings ensure that records are only accepted if their timestamps are within an allowed range, and prevent retention issues caused by records with timestamps that are too far in the past or future. By validating directly from record batches, Redpanda ensures:
-
Accurate, timestamp-based retention across clusters
-
Predictable and consistent data deletion behavior
-
Proper retention alignment for replicated and disaster recovery use cases
Clusters running versions prior to v25.3 may continue to use the broker timestamp (broker_timestamp), which is populated when the broker first receives the record.
You can also manually opt in clusters running versions prior to v25.3 to this new max_timestamp behavior using the Admin API:
curl --request PUT http://localhost:9644/v1/features/validated_batch_timestamps -d '{"state":"active"}'| When manually opting in clusters running versions prior to v25.3, it is particularly important for users of MirrorMaker2 and Shadowing to enable this feature flag on their destination clusters. Without this feature flag, active clusters created by MirrorMaker2 that are running versions prior to v25.3 will have retention enforced from the date of cluster creation rather than the date of the data. You can see this if you compare the data present on the original cluster versus the newly-replicated cluster, as it will show a difference in retention enforcement. |
|
Make sure that all of the produced data sent to
|
To set retention time for a single topic, use retention.ms, which overrides log_retention_ms.
-
retention.ms- Topic-level property that specifies how long a message stays on disk before it’s deleted.To minimize the likelihood of out-of-disk outages, set
retention.msto86400000, which is one day. There is no default.To set
retention.mson an individual topic:rpk topic alter-config <topic> --set retention.ms=<retention_time> -
log_retention_ms- Cluster-level property that specifies how long a message stays on disk before it’s deleted.To minimize the likelihood of out-of-disk outages, set
log_retention_msto86400000, which is one day. The default is604800000, which is one week.
Do not set log_retention_ms to -1 unless you’re using remote write with Tiered Storage to upload segments to object storage. Setting it to -1 configures indefinite retention, which can fill disk space.
|
See also:
Set size-based retention
Messages are eligible for deletion after the storage size of the partition containing them exceeds the value specified in retention_bytes (the cluster-level property) or retention.bytes (the topic-level property). If retention.bytes is not set at the topic level, the topic inherits the retention_bytes setting. Segments are deleted in chronological order until the partition is back under the specified size limit.
-
retention.bytes- Topic-level property that specifies the maximum size of a partition. There is no default.To set
retention.bytes:rpk topic alter-config <topic> --set retention.bytes=<retention_size> -
retention_bytes- Cluster-level property that specifies the maximum size of a partition.Set this to a value that is lower than the disk capacity, or a fraction of the disk capacity based on the number of partitions per topic. For example, if you have one partition,
retention_bytescan be 80% of the disk size. If you have 10 partitions, it can be 80% of the disk size divided by 10. The default isnull, which means that retention based on topic size is disabled.To set
retention_bytes:rpk cluster config set retention_bytes <retention_size>
Configure offset retention
Redpanda supports consumer group offset retention through both periodic offset expiration and the Kafka OffsetDelete API.
For periodic offset expiration, set the retention duration of consumer group offsets and the check period. Redpanda identifies offsets that are expired and removes them to reclaim storage. For a consumer group, the retention timeout starts from when the group becomes empty as a consequence of losing all its consumers. For a standalone consumer, the retention timeout starts from the time of the last commit. Once elapsed, an offset is considered to be expired and is discarded.
| Property | Description |
|---|---|
Period at which Redpanda checks for expired consumer group offsets. |
|
Retention duration of consumer group offsets. |
|
Enable group offset retention for Redpanda clusters upgraded from versions prior to v23.1. |
Redpanda supports group offset deletion with the Kafka OffsetDelete API through rpk with the rpk group offset-delete command. The offset delete API provides finer control over culling consumer offsets. For example, it enables the manual removal of offsets that are tracked by Redpanda within the __consumer_offsets topic. The offsets requested to be removed will be removed only if either the group in question is in a dead state, or the partitions being deleted have no active subscriptions.
Manage transaction coordinator disk usage
Redpanda uses the internal topic kafka_internal/tx to store transaction metadata for exactly-once and transactional producers. The log files contain all historical transactions, both committed and current open ones. Over time, this topic can consume excessive disk space in niche use cases that generate a large number of transactional sessions.
You can manage the disk usage of kafka_internal/tx by tuning the following cluster properties:
-
transaction_coordinator_delete_retention_ms. Default:604800000(7 days). -
transactional_id_expiration_ms. Default:604800000(7 days).
To mitigate unbounded growth of kafka_internal/tx disk usage and manage its storage consumption more effectively, monitor your storage metrics and lower the values of the relevant properties as needed.
To adjust these properties, run:
rpk cluster config set transaction_coordinator_delete_retention_ms=<milliseconds> transactional_id_expiration_ms=<milliseconds>Configure segment size
The log_segment_size property specifies the size of each log segment within the partition. Redpanda closes segments after they exceed this size and messages begin filling a new segment.
To set log_segment_size:
rpk cluster config set log_segment_size <segment_size>If you know which topics will receive more data, it’s best to specify the size for each topic.
To configure log segment size on a topic:
rpk topic alter-config <topic> --set segment.bytes=<segment_size>Segment size for compacted topics
Compaction, or key-based retention, saves space by retaining at least the most recent value for a message key within a topic partition’s log and discarding older values. Compaction runs periodically in the background in a best effort fashion, and it doesn’t guarantee that there are no duplicate values per key.
When compaction is configured, topics take their size from compacted_log_segment_size. The log_segment_size property does not apply to compacted topics.
When compaction executes, one or more segments are merged into one new compacted segment. The old segments are deleted. The size of the initial segments are controlled by segment.bytes. The max_compacted_log_segment_size property controls how many segments are merged together. For example, if you set segment.bytes to 128 MB, but leave max_compacted_log_segment_size at 5 GB, fresh segments are 128 MB but merged segments may grow up to 5 GB after compaction.
Redpanda periodically performs compaction in the background. The compaction period is configured by the cluster property log_compaction_interval_ms.
Keep in mind that very large segments delay, or possibly prevent, compaction. A very large active segment cannot be cleaned up or compacted until it is closed, and very large closed segments require significant memory and CPU to process for compaction. Very small segments increase the frequency of processing for applying compaction and resource limits. To calculate an upper limit on segment size, divide the disk size by the number of partitions. For example, if you have a 128 GB disk and 1000 partitions, the upper limit of the segment size is 134217728. Default is 1073741824.
For details about how to modify cluster configuration properties, see Cluster configuration.
For further information on how compaction works, see Compaction tuning.
Log rolling
Writing data for a topic usually spans multiple log segments. An active segment of a topic is a log segment that is being written to. As data of a topic is written and an active segment becomes full (reaches log_segment_size), it’s closed and changed to read-only mode. A new segment is created and set to read-write mode, and it becomes the active segment. Log rolling is the rotation between segments to create a new active segment.
Configurable timeouts can also trigger log rolling. This is useful when applying topic retention limits within a known fixed duration. A log rolling timeout starts from the first write to an active segment. When a timeout elapses before the segment is full, the segment is rolled. The timeouts are configured with cluster-level and topic-level properties:
-
log_segment_ms (or
log.roll.ms) is a cluster property that configures the default segment rolling timeout for all topics of a cluster.To set
log_segment_msfor all topics of a cluster for a duration in milliseconds:rpk cluster config set log_segment_ms <segment_ms_duration> -
segment.msis a topic-level property that configures the default segment rolling timeout for one topic. It’s not set by default. If set, it overrideslog_segment_ms.To set
segment.msfor a topic:rpk topic alter-config <topic> --set segment.ms=<segment_ms_duration> -
log_segment_ms_min and log_segment_ms_max are cluster-level properties that configure the lower and upper limits, respectively, of log rolling timeouts.
Space management
| Space management only works when Tiered Storage is enabled on all topics. Space management and the housekeeping process only considers removing data that is safely stored in Tiered Storage. |
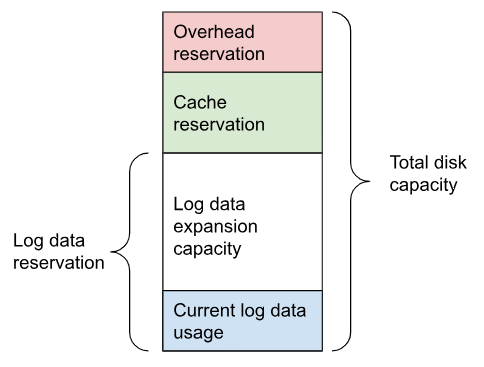
The goal of space management is to utilize the local disk space as a cache. It works alongside Tiered Storage to provide faster access to recent data, while making sure that local disk space is managed in accordance with retention policies and other processes, such as Continuous Data Balancing and decommissioning.
Space management divides the disk space into different areas that can be managed separately:
-
Reserved disk space (
disk_reservation_percent) is the area of disk space that Redpanda does not use.-
As the disk space used by the other areas grows to their target sizes, the reserved space provides buffer space to avoid free disk space alerts.
-
SSDs that run near capacity can experience performance degradation, so this buffer space prevents the disks from running at capacity.
-
-
Cache storage (the minimum of
cloud_storage_cache_size_percentorcloud_storage_cache_size) is the maximum size of the disk cache used by Tiered Storage. As the cache reaches its limit, new data added to the cache removes old data from the cache. -
Log storage (the minimum of
retention_local_target_capacity_percentorretention_local_target_capacity_bytes) is the area of disk space used for topic data. This is typically 70-80% of total disk space.
Log segment eviction occurs in each of the following phases. As soon as log storage usage falls below the target, the eviction process ends.
Redpanda’s space management features are enabled with the space_management_enable parameter. As of Redpanda v23.3.2, all new clusters default this value to true. When upgrading from older versions, ensure this parameter is set to true if you wish to make use of space management as described here. Alternatively, if you wish to explicitly disable these features, set this property to false.
|
See also: Object storage housekeeping
Phases of data removal
Phase 1: Follow retention policy
A housekeeping process in Redpanda periodically performs compaction and removes partition data that has expired according to your retention policy. This applies to both Tiered Storage and non-Tiered Storage topics. Space management attempts to apply retention to partitions in the order that removes the largest amount of data.
-
When
retention_local_strictis false (default), the housekeeping process removes data above the configured log storage reservation. -
When
retention_local_strictis true, the housekeeping process uses local retention settings to select what data to remove.The retention_local_strictproperty is set to true in clusters upgraded from release23.1and earlier.
Phase 2: Trim to local retention
This phase removes partition data that exceeds the effective local retention policy. This includes the explicit retention settings applied to a topic, as well as the cluster-level defaults, which are assigned to any topic that does not have explicit topic-level overrides.
-
When
retention_local_strictis false (default), the retention policy was met in the previous phase, so no more data is removed. -
When
retention_local_strictis true, the housekeeping process removes data fairly across all topics until each topic reaches its local retention target.
After this phase completes, all partitions are operating at a size that reflects their effective local retention target. The next phase starts to override the local retention settings to remove more data.
Phase 3: Trim data with default local retention settings
For topics with the default local retention settings, this phase removes partition data to a low-space level, which is a configured size of two log segments that provide minimal space for partition operation. The housekeeping process only considers removing data that is safely stored in Tiered Storage.
Monitor disk space
You can check your total disk size and free space by viewing the metrics:
-
redpanda_storage_disk_total_bytes -
redpanda_storage_disk_free_bytes
Redpanda monitors disk space and updates these metrics and the storage_space_alert status based on your full disk alert threshold. You can check the alert status with the redpanda_storage_disk_free_space_alert metric. The alert values are:
-
0 = No alert
-
1 = Low free space alert
-
2 = Out of space (degraded, external writes are rejected)
Set free disk space thresholds
You can set a soft limit for a minimum free disk space alert. This soft limit generates an error message and affects the value of the redpanda_storage_disk_free_space_alert metric. You can also set a hard limit for minimum disk space, after which Redpanda enters a degraded performance state. You set the thresholds for these values by configuring the following properties, which you can set on any data disk (one drive per node):
| Property | Description |
|---|---|
|
Minimum free disk space threshold, in bytes, for generating a low disk space alert. |
|
Minimum free disk space allowed, in percentage of total available space for that drive, for generating a low disk space alert. |
|
Disk space threshold beyond which a degraded performance state is entered. |
| The alert threshold can be set in either bytes or percentage of total space. To disable one threshold in favor of the other, set it to zero. |
When a disk exceeds the configured alert threshold, Redpanda updates the redpanda_storage_disk_free_space_alert metric to 1, indicating low free space, and writes an error level storage space alert message to the service log. The message looks like the following:
ERROR 2023-12-08 15:07:45,716 [shard 0] cluster - storage space alert: free space at 25.574% on /var/lib/redpanda/data: 96.732GiB total, 24.739GiB free, min. free 0.000bytes. Be sure to adjust retention policies as needed to avoid running out of space.If you continue to exhaust disk space and reach the storage_min_free_bytes value, the redpanda_storage_disk_free_space_alert metric changes to 2, indicating Redpanda is in a degraded performance state. See Handle full disks for more information on addressing this situation.
Once disk space is freed, Redpanda updates the redpanda_storage_disk_free_space_alert metric accordingly.
Handle full disks
If you exceed your low disk space threshold, Redpanda blocks clients from producing. In that state, Redpanda returns errors to external writers, but it still allows internal write traffic, such as replication and rebalancing.
The storage_min_free_bytes tunable configuration property sets the low disk space threshold—the hard limit—for this write rejection. The default value is 5 GiB, which means that when any broker’s free space falls below 5 GiB, Redpanda rejects writes to all brokers.
Create a ballast file
A ballast file is an empty file that takes up disk space. If Redpanda runs out of disk space and becomes unavailable, you can delete the ballast file as a last resort. This clears up some space and gives you time to delete topics or records and change your retention properties.
To create a ballast file, set the following properties in the rpk section of the redpanda.yaml file:
rpk:
tune_ballast_file: true
ballast_file_path: "/var/lib/redpanda/data/ballast"
ballast_file_size: "1GiB"Run rpk to create the ballast file:
rpk redpanda tune ballast_file| Property | Description |
|---|---|
|
Set to |
|
You can change the location of the ballast file, but it must be on the same mount point as the Redpanda data directory. Default is |
|
Increase the ballast file size if it is a very high-throughput cluster. Decrease the ballast file size if you have very little storage space. The ballast file should be large enough to give you time to delete data and reconfigure retention properties if Redpanda crashes, but small enough that you don’t waste disk space. In general, set this to approximately 10 times the size of the largest segment, to have enough space to compact that topic. Default is |
