How Data Transforms Work
Redpanda provides the framework to build and deploy inline transformations (data transforms) on data written to Redpanda topics, delivering processed and validated data to consumers in the format they expect. Redpanda does this directly inside the broker, eliminating the need to manage a separate stream processing environment or use third-party tools.
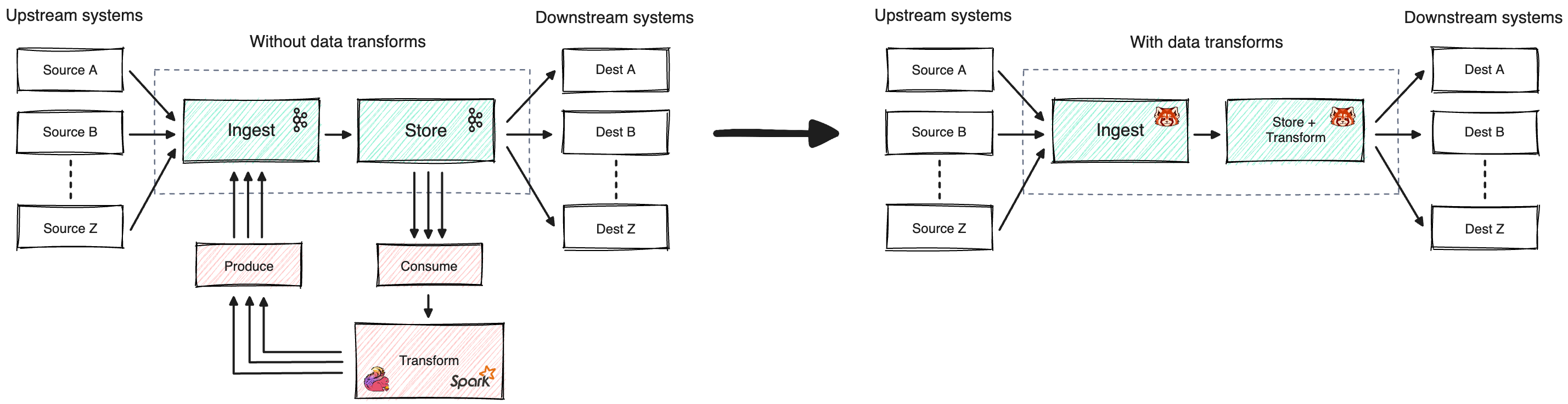
Data transforms let you run common data streaming tasks, like filtering, scrubbing, and transcoding, within Redpanda. For example, you may have consumers that require you to redact credit card numbers or convert JSON to Avro. Data transforms can also interact with the Redpanda Schema Registry to work with encoded data types. To learn how to build and deploy data transforms, see Data Transforms in Linux Quickstart.
Data transforms with WebAssembly
Data transforms use WebAssembly (Wasm) engines inside a Redpanda broker, allowing Redpanda to control the entire transform lifecycle. For example, Redpanda can stop and start transforms when partitions are moved or to free up system resources for other tasks.
Data transforms take data from an input topic and map it to one or more output topics. For each topic partition, a leader is responsible for handling the data. Redpanda runs a Wasm virtual machine (VM) on the same CPU core (shard) as these partition leaders to execute the transform function.
Transform functions are the specific implementations of code that carry out the transformations. They read data from input topics, apply the necessary processing logic, and write the transformed data to output topics.
To execute a transform function, Redpanda uses just-in-time (JIT) compilation to compile the bytecode in memory, write it to an executable space, then run the directly translated machine code. This JIT compilation ensures efficient execution of the machine code, as it is tailored to the specific hardware it runs on.
When you deploy a data transform to a Redpanda broker, it stores the Wasm bytecode and associated metadata, such as input and output topics and environment variables. The broker then replicates this data across the cluster using internal Kafka topics. When the data is distributed, each shard runs its own instance of the transform function. This process includes several resource management features:
-
Each shard can run only one instance of the transform function at a time to ensure efficient resource utilization and prevent overload.
-
Memory for each function is reserved within the broker with the
data_transforms_per_core_memory_reservationanddata_transforms_per_function_memory_limitproperties. See Configure memory for data transforms. -
CPU time is dynamically allocated to the Wasm runtime to ensure that the code does not run forever and cannot block the broker from handling traffic or doing other work, such as Tiered Storage uploads.
Flow of data transforms
When a shard becomes the leader of a given partition on the input topic of one or more active transforms, Redpanda does the following:
-
Spins up a Wasm VM using the JIT-compiled Wasm module.
-
Pushes records from the input partition into the Wasm VM.
-
Writes the output. The output partition may exist on the same broker or on another broker in the cluster.
Within Redpanda, a single Raft controller manages cluster information, including data transforms. On every shard, Redpanda knows what data transforms exist in the cluster, as well as metadata about the transform function, such as input and output topics and environment variables.
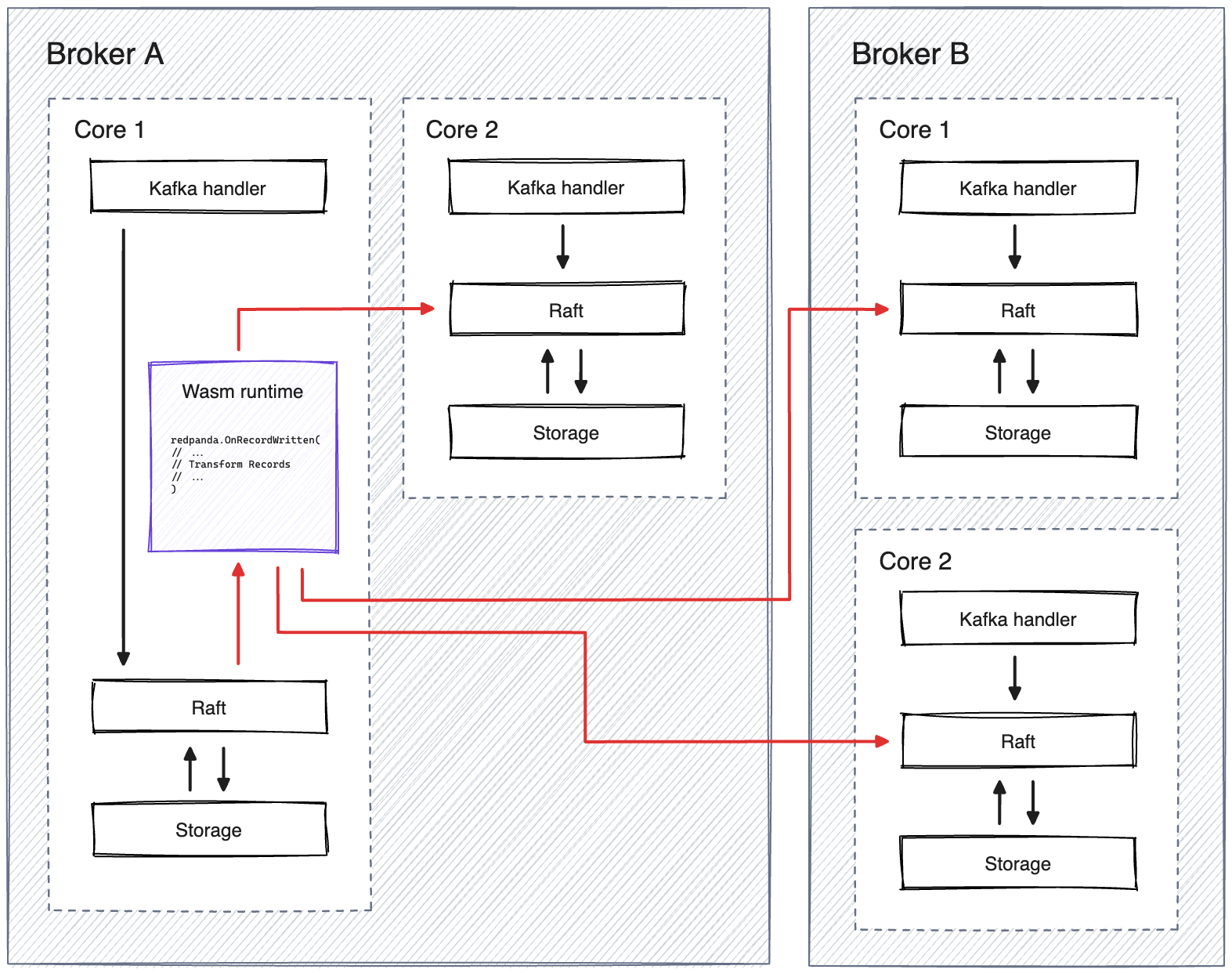
Each transform function reads from a specified input topic and writes to a specified output topic. The transform function processes every record produced to an input topic and returns zero or more records that are then produced to the specified output topic. Data transforms are applied to all partitions on an input topic. A record is processed after it has been successfully written to disk on the input topic. Because the transform happens in the background after the write finishes, the transform doesn’t affect the original produced record, doesn’t block writes to the input topic, and doesn’t block produce and consume requests.
A new transform function reads the input topic from the latest offset. That is, it only reads new data produced to the input topic: it does not read records produced to the input topic before the transform was deployed. If a partition leader moves from one broker to another, then the instance of the transform function assigned to that partition moves with it.
When a partition replica loses leadership, the broker hosting that partition replica stops the instance of the transform function running on the same shard. The broker that is now hosting the partition’s new leader starts the transform function on the same shard as that leader, and the transform function resumes from the last committed offset.
If the previous instance of the transform function failed to commit its latest offsets before moving with the partition leader (for example, if the broker crashed), then it’s likely that the new instance will reprocess some events. For broker failures, transform functions have at-least-once semantics, because records are retried from the committed last offset, and offsets are committed periodically. For more information, see Data Transforms in Linux Quickstart.
Limitations
This section outlines the limitations of data transforms. These constraints are categorized into general limitations affecting the overall functionality and specific limitations related to giving data transforms access to custom environment variables.
General
-
No external access: Transform functions have no external access to disk or network resources.
-
Single message transforms: Only single record transforms are supported, but multiple output records from a single input record are supported. For aggregations, joins, or complex transformations, consider using Redpanda Connect or Apache Flink.
-
Output topic limit: Up to eight output topics are supported.
-
Delivery semantics: Transform functions have at-least-once delivery.
-
Transactions API: When clients use the Kafka Transactions API on partitions of an input topic, transform functions process only committed records.
JavaScript
-
No native extensions: Native Node.js extensions are not supported. Packages that require compiling native code or interacting with low-level system features cannot be used.
-
Limited Node.js standard modules: Only modules that can be polyfilled by the esbuild plugin can be used. Even if a module can be polyfilled, certain functionalities, such as network connections, will not work because the necessary browser APIs are not exposed in the Redpanda JavaScript runtime environment. For example, while the plugin can provide stubs for some Node.js modules such as
httpandprocess, these stubs will not work in the Redpanda JavaScript runtime environment. -
No write options: The JavaScript SDK does not support write options, such as specifying which output topic to write to.
Environment variables
-
Maximum number of variables: You can set up to 128 custom environment variables.
-
Reserved prefix: Variable keys must not start with
REDPANDA_. This prefix is reserved for built-in environment variables. -
Key length: Each key must be less than 128 bytes in length.
-
Total value length: The combined length of all values for the environment variables must be less than 2000 bytes.
-
Encoding: All keys and values must be encoded in UTF-8.
-
Control characters: Keys and values must not contain any control characters, such as null bytes.
