Monitor Redpanda in Kubernetes
Redpanda exports metrics through two endpoints on the Admin API port (default: 9644) for you to monitor system health and optimize system performance.
|
Use /public_metrics for your primary dashboards for monitoring system health. These metrics have low cardinality and are designed for customer consumption, with aggregated labels for better performance. Public metrics use the Use /metrics for detailed analysis and debugging. These metrics can have high cardinality with thousands of series, providing granular operational insights. Internal metrics use the |
The /metrics endpoint is a legacy endpoint that includes many internal metrics that are unnecessary for a typical Redpanda user to monitor. The /metrics endpoint is also referred to as the 'internal metrics' endpoint, and Redpanda recommends that you use it for development, testing, and analysis. Alternatively, the /public_metrics endpoint provides a smaller set of important metrics that can be queried and ingested more quickly and inexpensively.
|
To maximize monitoring performance by minimizing the cardinality of data, some metrics are exported when their underlying features are in use, and are not exported when not in use. For example, a metric for consumer groups, When monitoring internal metrics, consider enabling aggregate_metrics to reduce the cardinality of data to monitor. |
This topic covers the following about monitoring Redpanda metrics:
Configure Prometheus
Prometheus is a system monitoring and alerting tool. It collects and stores metrics as time-series data identified by a metric name and key/value pairs.
To configure Prometheus to monitor Redpanda metrics in Kubernetes, you can use the Prometheus Operator:
-
Follow the steps to deploy the Prometheus Operator.
Make sure to configure the Prometheus resource to target your Redpanda cluster:
prometheus.yamlapiVersion: monitoring.coreos.com/v1 kind: Prometheus metadata: name: prometheus spec: serviceAccountName: prometheus serviceMonitorNamespaceSelector: matchLabels: name: <namespace> serviceMonitorSelector: matchLabels: app.kubernetes.io/name: redpanda resources: requests: memory: 400Mi enableAdminAPI: false-
serviceMonitorNamespaceSelector.matchLabels.name: The namespace in which you will deploy Redpanda. The Prometheus Operator looks for ServiceMonitor resources in this namespace. -
serviceMonitorSelector.matchLabels.app.kubernetes.io/name: The value offullnameOverridein your Redpanda Helm chart. The default isredpanda. The Redpanda Helm chart creates the ServiceMonitor resource with this label.
-
-
Deploy Redpanda with monitoring enabled to deploy the ServiceMonitor resource:
-
Operator
-
Helm
redpanda-cluster.yamlapiVersion: cluster.redpanda.com/v1alpha2 kind: Redpanda metadata: name: redpanda spec: chartRef: {} clusterSpec: monitoring: enabled: true scrapeInterval: 30skubectl apply -f redpanda-cluster.yaml --namespace <namespace>-
--values
-
--set
prometheus-monitoring.yamlmonitoring: enabled: true scrapeInterval: 30shelm upgrade --install redpanda redpanda/redpanda --namespace <namespace> --create-namespace \ --values prometheus-monitoring.yaml --reuse-valueshelm upgrade --install redpanda redpanda/redpanda \ --namespace <namespace> \ --create-namespace \ --set monitoring.enabled=true \ --set monitoring.scrapeInterval="30s" -
-
Wait until all Pods are running:
kubectl -n <namespace> rollout status statefulset redpanda --watch -
Ensure that the ServiceMonitor was deployed:
kubectl get servicemonitor --namespace <namespace> -
Ensure that you’ve exposed the Prometheus Service.
-
Expose the Prometheus server to your localhost:
kubectl port-forward svc/prometheus 9090 -
Open Prometheus, and see that Prometheus is scraping metrics from your Redpanda endpoints.
Generate Grafana dashboard
Grafana is a tool to query, visualize, and generate alerts for metrics.
Redpanda supports generating Grafana dashboards from its metrics endpoints with rpk generate grafana-dashboard.
To generate a comprehensive Grafana dashboard, run the following command and pipe the output to a file that can be imported into Grafana:
rpk generate grafana-dashboard --datasource <name> --metrics-endpoint <url> > <output-file>-
<name>is the name of the Prometheus data source configured in your Grafana instance. -
<url>is the address to a Redpanda broker’s metrics endpoint (public or internal). -
For
/public_metrics, for example, run the following command:rpk generate grafana-dashboard \ --datasource prometheus \ --metrics-endpoint <broker-address>:9644/public_metrics > redpanda-dashboard.json -
For
/metrics, for example, run the following command:rpk generate grafana-dashboard \ --datasource prometheus \ --metrics-endpoint <broker-address>:9644/metrics > redpanda-dashboard.json
For details about the command, see rpk generate grafana-dashboard.
In Grafana, import the generated JSON file to create a dashboard. Out of the box, Grafana generates panels tracking latency for 50%, 95%, and 99% (based on the maximum latency set), throughput, and error segmentation by type.
To use the imported dashboard to create new panels:
-
Click + in the left pane, and select Add a new panel.
-
On the Query tab, select Prometheus data source.
-
Decide which metric you want to monitor, click Metrics browser, and type
redpandato show available public metrics (orvectorizedfor internal metrics) from the Redpanda cluster.
Use Redpanda monitoring examples
For hands-on learning, Redpanda provides a repository with examples of monitoring Redpanda with Prometheus and Grafana: redpanda-data/observability.
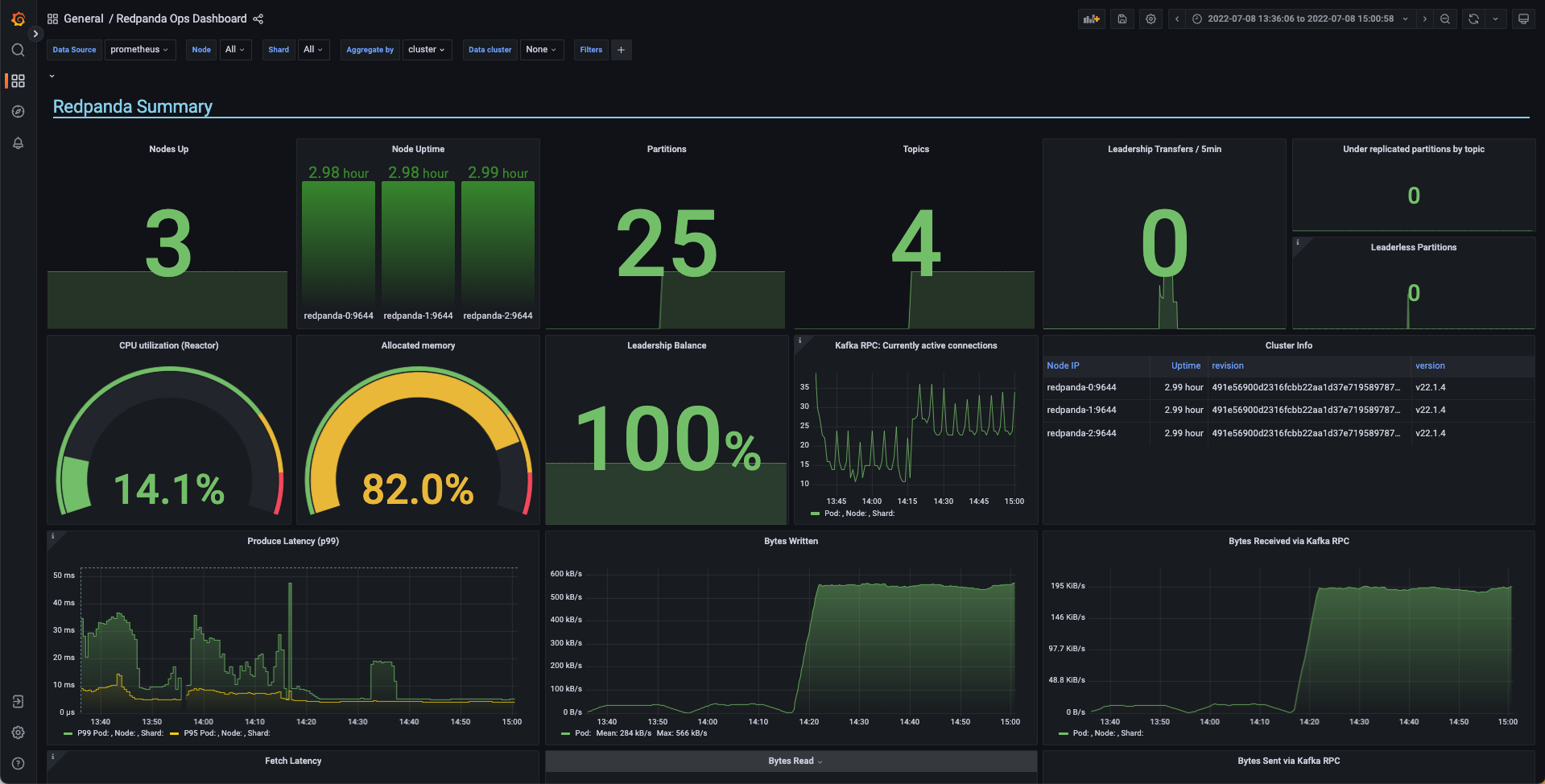
It includes example Grafana dashboards and a sandbox environment in which you launch a Dockerized Redpanda cluster and create a custom workload to monitor with dashboards.
Monitor for performance and health
This section provides guidelines and example queries using Redpanda’s public metrics to optimize your system’s performance and monitor its health.
To help detect and mitigate anomalous system behaviors, capture baseline metrics of your healthy system at different stages (at start-up, under high load, in steady state) so you can set thresholds and alerts according to those baselines.
|
For counter type metrics, a broker restart causes the count to reset to zero in tools like Prometheus and Grafana. Redpanda recommends wrapping counter metrics in a rate query to account for broker restarts, for example: |
Redpanda architecture
Understanding the unique aspects of Redpanda’s architecture and data path can improve your performance, debugging, and tuning skills:
-
Redpanda replicates partitions across brokers in a cluster using Raft, where each partition is a Raft consensus group. A message written from the Kafka API flows down to the Raft implementation layer that eventually directs it to a broker to be stored. Metrics about the Raft layer can reveal the health of partitions and data flowing within Redpanda.
-
Redpanda is designed with a thread-per-core model that it implements with the Seastar library. With each application thread pinned to a CPU core, when observing or analyzing the behavior of a specific application, monitor the relevant metrics with the label for the specific shard, if available.
Infrastructure resources
The underlying infrastructure of your system should have sufficient margins to handle peaks in processing, storage, and I/O loads. Monitor infrastructure health with the following queries.
CPU usage
For the total CPU uptime, monitor redpanda_uptime_seconds_total. Monitoring its rate of change with the following query can help detect unexpected dips in uptime:
rate(redpanda_uptime_seconds_total[5m])For the total CPU busy (non-idle) time, monitor redpanda_cpu_busy_seconds_total.
To detect unexpected idling, you can query the rate of change as a fraction of the shard that is in use at a given point in time.
rate(redpanda_cpu_busy_seconds_total[5m])|
While CPU utilization at the host-level might appear high (for example, 99-100% utilization) when I/O events like message arrival occur, the actual Redpanda process utilization is likely low. System-level metrics such as those provided by the This high host-level CPU utilization happens because Redpanda uses Seastar, which runs event loops on every core (also referred to as a reactor), constantly polling for the next task. This process never blocks and will increment clock ticks. It doesn’t necessarily mean that Redpanda is busy. Use |
Memory availability and pressure
To monitor memory, use redpanda_memory_available_memory, which includes both free memory and reclaimable memory from the batch cache. This provides a more accurate picture of memory pressure than redpanda_memory_allocated_memory, which can appear high because it counts reclaimable batch cache memory that could be freed if needed.
To monitor the fraction of memory available:
min(redpanda_memory_available_memory / (redpanda_memory_free_memory + redpanda_memory_allocated_memory))To monitor memory pressure (fraction of memory being used), which may be more intuitive for alerting:
min(redpanda_memory_available_memory / redpanda_memory_allocated_memory)You can also monitor the lowest available memory available since the process started to understand historical memory pressure:
min(redpanda_memory_available_memory_low_water_mark / (redpanda_memory_free_memory + redpanda_memory_allocated_memory))Disk used
To monitor the fraction of disk consumed, use a formula with redpanda_storage_disk_free_bytes and redpanda_storage_disk_total_bytes:
1 - (sum(redpanda_storage_disk_free_bytes) / sum(redpanda_storage_disk_total_bytes))Also monitor redpanda_storage_disk_free_space_alert for an alert when available disk space is low or degraded.
IOPS
For read and write I/O operations per second (IOPS), monitor the redpanda_io_queue_total_read_ops and redpanda_io_queue_total_write_ops counters:
rate(redpanda_io_queue_total_read_ops[5m]),
rate(redpanda_io_queue_total_write_ops[5m])Throughput
While maximizing the rate of messages moving from producers to brokers then to consumers depends on tuning each of those components, the total throughput of all topics provides a system-level metric to monitor. When you observe abnormal, unhealthy spikes or dips in producer or consumer throughput, look for correlation with changes in the number of active connections (redpanda_rpc_active_connections) and logged errors to drill down to the root cause.
The total throughput of a cluster can be measured by the producer and consumer rates across all topics.
To observe the total producer and consumer rates of a cluster, monitor redpanda_rpc_received_bytes for producer traffic and redpanda_rpc_sent_bytes for consumer traffic. Filter both metrics using the redpanda_server label with the value kafka.
Producer throughput
For the produce rate, create a query to get the produce rate across all topics:
rate(redpanda_rpc_received_bytes{redpanda_server="kafka"}[$__rate_interval])Consumer throughput
For the consume rate, create a query to get the total consume rate across all topics:
rate(redpanda_rpc_sent_bytes{redpanda_server="kafka"}[$__rate_interval])Identify high-throughput clients
Use rpk cluster connections list or the ListKafkaConnections endpoint in Admin API to identify which client connections are driving the majority of, or the change in, the produce or consume throughput for a cluster.
For example, to list connections with a current produce throughput greater than 1MB, run:
-
rpk
-
curl
rpk cluster connections list --filter-raw="recent_request_statistics.produce_bytes > 1000000" --order-by="recent_request_statistics.produce_bytes desc"UID STATE USER CLIENT-ID IP:PORT NODE SHARD OPEN-TIME IDLE PROD-TPUT/SEC FETCH-TPUT/SEC REQS/MIN
b20601a3-624c-4a8c-ab88-717643f01d56 OPEN UNAUTHENTICATED perf-producer-client 127.0.0.1:55012 0 0 9s 0s 78.9MB 0B 292curl -s -X POST "localhost:9644/redpanda.core.admin.v2.ClusterService/ListKafkaConnections" --header "Content-Type: application/json" --data '{"filter":"recent_request_statistics.produce_bytes > 1000000", "order_by":"recent_request_statistics.produce_bytes desc"}' | jqShow example API response
{
"connections": [
{
"nodeId": 0,
"shardId": 0,
"uid": "b20601a3-624c-4a8c-ab88-717643f01d56",
"state": "KAFKA_CONNECTION_STATE_OPEN",
"openTime": "2025-10-15T14:15:15.755065000Z",
"closeTime": "1970-01-01T00:00:00.000000000Z",
"authenticationInfo": {
"state": "AUTHENTICATION_STATE_UNAUTHENTICATED",
"mechanism": "AUTHENTICATION_MECHANISM_UNSPECIFIED",
"userPrincipal": ""
},
"listenerName": "",
"tlsInfo": {
"enabled": false
},
"source": {
"ipAddress": "127.0.0.1",
"port": 55012
},
"clientId": "perf-producer-client",
"clientSoftwareName": "apache-kafka-java",
"clientSoftwareVersion": "3.9.0",
"transactionalId": "my-tx-id",
"groupId": "",
"groupInstanceId": "",
"groupMemberId": "",
"apiVersions": {
"18": 4,
"22": 3,
"3": 12,
"24": 3,
"0": 7
},
"idleDuration": "0s",
"inFlightRequests": {
"sampledInFlightRequests": [
{
"apiKey": 0,
"inFlightDuration": "0.000406892s"
}
],
"hasMoreRequests": false
},
"totalRequestStatistics": {
"produceBytes": "78927173",
"fetchBytes": "0",
"requestCount": "4853",
"produceBatchCount": "4849"
},
"recentRequestStatistics": {
"produceBytes": "78927173",
"fetchBytes": "0",
"requestCount": "4853",
"produceBatchCount": "4849"
}
}
]
}You can adjust the filter and sorting criteria as necessary.
Latency
Latency should be consistent between produce and fetch sides. It should also be consistent over time. Take periodic snapshots of produce and fetch latencies, including at upper percentiles (95%, 99%), and watch out for significant changes over a short duration.
In Redpanda, the latency of produce and fetch requests includes the latency of inter-broker RPCs that are born from Redpanda’s internal implementation using Raft.
Kafka consumer latency
To monitor Kafka consumer request latency, use the redpanda_kafka_request_latency_seconds histogram with the label redpanda_request="consume". For example, create a query for the 99th percentile:
histogram_quantile(0.99, sum(rate(redpanda_kafka_request_latency_seconds_bucket{redpanda_request="consume"}[5m])) by (le, provider, region, instance, namespace, pod))You can monitor the rate of Kafka consumer requests using redpanda_kafka_request_latency_seconds_count with the redpanda_request="consume" label:
rate(redpanda_kafka_request_latency_seconds_count{redpanda_request="consume"}[5m])
Kafka producer latency
To monitor Kafka producer request latency, use the redpanda_kafka_request_latency_seconds histogram with the redpanda_request="produce" label. For example, create a query for the 99th percentile:
histogram_quantile(0.99, sum(rate(redpanda_kafka_request_latency_seconds_bucket{redpanda_request="produce"}[5m])) by (le, provider, region, instance, namespace, pod))You can monitor the rate of Kafka producer requests with redpanda_kafka_request_latency_seconds_count with the redpanda_request="produce" label:
rate(redpanda_kafka_request_latency_seconds_count{redpanda_request="produce"}[5m])Internal RPC latency
To monitor Redpanda internal RPC latency, use the redpanda_rpc_request_latency_seconds histogram with
the redpanda_server="internal" label. For example, create a query for the 99th percentile latency:
histogram_quantile(0.99, (sum(rate(redpanda_rpc_request_latency_seconds_bucket{redpanda_server="internal"}[5m])) by (le, provider, region, instance, namespace, pod)))You can monitor the rate of internal RPC requests with redpanda_rpc_request_latency_seconds histogram’s count:
rate(redpanda_rpc_request_latency_seconds_count[5m])Partition health
The health of Kafka partitions often reflects the health of the brokers that host them. Thus, when alerts occur for conditions such as under-replicated partitions or more frequent leadership transfers, check for unresponsive or unavailable brokers.
With Redpanda’s internal implementation of the Raft consensus protocol, the health of partitions is also reflected in any errors in the internal RPCs exchanged between Raft peers.
Leadership changes
Stable clusters have a consistent balance of leaders across all brokers, with few to no leadership transfers between brokers.
To observe changes in leadership, monitor the redpanda_raft_leadership_changes counter. For example, use a query to get the total rate of increase of leadership changes for a cluster:
sum(rate(redpanda_raft_leadership_changes[5m]))Under-replicated partitions
A healthy cluster has partition data fully replicated across its brokers.
An under-replicated partition is at higher risk of data loss. It also adds latency because messages must be replicated before being committed. To know when a partition isn’t fully replicated, create an alert for the redpanda_kafka_under_replicated_replicas gauge when it is greater than zero:
redpanda_kafka_under_replicated_replicas > 0Under-replication can be caused by unresponsive brokers. When an alert on redpanda_kafka_under_replicated_replicas is triggered, identify the problem brokers and examine their logs.
Leaderless partitions
A healthy cluster has a leader for every partition.
A partition without a leader cannot exchange messages with producers or consumers. To identify when a partition doesn’t have a leader, create an alert for the redpanda_cluster_unavailable_partitions gauge when it is greater than zero:
redpanda_cluster_unavailable_partitions > 0Leaderless partitions can be caused by unresponsive brokers. When an alert on redpanda_cluster_unavailable_partitions is triggered, identify the problem brokers and examine their logs.
Raft RPCs
Redpanda’s Raft implementation exchanges periodic status RPCs between a broker and its peers. The redpanda_node_status_rpcs_timed_out gauge increases when a status RPC times out for a peer, which indicates that a peer may be unresponsive and may lead to problems with partition replication that Raft manages. Monitor for non-zero values of this gauge, and correlate it with any logged errors or changes in partition replication.
Consumer group lag
Consumer group lag is an important performance indicator that measures the difference between the broker’s latest (max) offset and the consumer group’s last committed offset. The lag indicates how current the consumed data is relative to real-time production. A high or increasing lag means that consumers are processing messages slower than producers are generating them. A decreasing or stable lag implies that consumers are keeping pace with producers, ensuring real-time or near-real-time data consumption.
By monitoring consumer lag, you can identify performance bottlenecks and make informed decisions about scaling consumers, tuning configurations, and improving processing efficiency.
A high maximum lag may indicate that a consumer is experiencing connectivity problems or cannot keep up with the incoming workload.
A high or increasing total lag (lag sum) suggests that the consumer group lacks sufficient resources to process messages at the rate they are produced. In such cases, scaling the number of consumers within the group can help, but only up to the number of partitions available in the topic. If lag persists despite increasing consumers, repartitioning the topic may be necessary to distribute the workload more effectively and improve processing efficiency.
Redpanda provides the following methods for monitoring consumer group lag:
-
Dedicated gauges: Redpanda brokers can internally calculate consumer group lag and expose two dedicated gauges. This method is recommended for environments where your observability platform does not support complex queries required to calculate the lag from offset metrics.
Enabling these gauges may add a small amount of additional processing overhead to the brokers.
-
Offset-based calculation: You can use your observability platform to calculate consumer group lag from offset metrics. Use this method if your observability platform supports functions, such as
max(), and you prefer to avoid additional processing overhead on the broker.
Dedicated gauges
Redpanda can internally calculate consumer group lag and expose it as two dedicated gauges.
-
redpanda_kafka_consumer_group_lag_max: Reports the maximum lag observed among all partitions for a consumer group. This metric helps pinpoint the partition with the greatest delay, indicating potential performance or configuration issues. -
redpanda_kafka_consumer_group_lag_sum: Aggregates the lag across all partitions, providing an overall view of data consumption delay for the consumer group.
To enable these dedicated gauges, you must enable consumer group metrics in your cluster properties. Add the following to your Redpanda configuration:
-
enable_consumer_group_metrics: A list of properties to enable for consumer group metrics. You must add theconsumer_lagproperty to enable consumer group lag metrics. -
consumer_group_lag_collection_interval_sec(optional): The interval in seconds for collecting consumer group lag metrics. The default is 60 seconds.Set this value equal to the scrape interval of your metrics collection system. Aligning these intervals ensures synchronized data collection, reducing the likelihood of missing or misaligned lag measurements.
For example:
-
Helm + Operator
-
Helm
redpanda-cluster.yamlapiVersion: cluster.redpanda.com/v1alpha2
kind: Redpanda
metadata:
name: redpanda
spec:
chartRef: {}
clusterSpec:
config:
cluster:
enable_consumer_group_metrics:
- group
- partition
- consumer_lagkubectl apply -f redpanda-cluster.yaml --namespace <namespace>-
--values
-
--set
enable-consumer-metrics.yamlconfig:
cluster:
enable_consumer_group_metrics:
- group
- partition
- consumer_laghelm upgrade --install redpanda redpanda/redpanda --namespace <namespace> --create-namespace \
--values enable-consumer-metrics.yaml --reuse-valueshelm upgrade --install redpanda redpanda/redpanda \
--namespace <namespace> \
--create-namespace \
--set config.cluster.enable_consumer_group_metrics[0]=group \
--set config.cluster.enable_consumer_group_metrics[1]=partition \
--set config.cluster.enable_consumer_group_metrics[2]=consumer_lagWhen these properties are enabled, Redpanda computes and exposes the redpanda_kafka_consumer_group_lag_max and redpanda_kafka_consumer_group_lag_sum gauges to the /public_metrics endpoint.
Offset-based calculation
If your environment is sensitive to the performance overhead of the dedicated gauges, use the offset-based calculation method to calculate consumer group lag. This method requires your observability platform to support functions like max().
Redpanda provides two metrics to calculate consumer group lag:
-
redpanda_kafka_max_offset: The broker’s latest offset for a partition. -
redpanda_kafka_consumer_group_committed_offset: The last committed offset for a consumer group on that partition.
For example, here’s a typical query to compute consumer lag:
max by(redpanda_namespace, redpanda_topic, redpanda_partition)(redpanda_kafka_max_offset{redpanda_namespace="kafka"}) - on(redpanda_topic, redpanda_partition) group_right max by(redpanda_group, redpanda_topic, redpanda_partition)(redpanda_kafka_consumer_group_committed_offset)Services
Monitor the health of specific Redpanda services with the following metrics.
Schema Registry
Schema Registry request latency:
histogram_quantile(0.99, (sum(rate(redpanda_schema_registry_request_latency_seconds_bucket[5m])) by (le, provider, region, instance, namespace, pod)))Schema Registry request rate:
rate(redpanda_schema_registry_request_latency_seconds_count[5m]) + sum without(redpanda_status)(rate(redpanda_schema_registry_request_errors_total[5m]))Schema Registry request error rate:
rate(redpanda_schema_registry_request_errors_total[5m])REST proxy
REST proxy request latency:
histogram_quantile(0.99, (sum(rate(redpanda_rest_proxy_request_latency_seconds_bucket[5m])) by (le, provider, region, instance, namespace, pod)))REST proxy request rate:
rate(redpanda_rest_proxy_request_latency_seconds_count[5m]) + sum without(redpanda_status)(rate(redpanda_rest_proxy_request_errors_total[5m]))REST proxy request error rate:
rate(redpanda_rest_proxy_request_errors_total[5m])